Hail, fellow adventurers: to prove I do something more than just draw and write, I'd like to send out a reminder of the Second Embodied AI Workshop at the CVPR 2021 computer vision conference. In the last ten years, artificial intelligence has made great advances in recognizing objects, understanding the basics of speech and language, and recommending things to people. But interacting with the real world presents harder problems: noisy sensors, unreliable actuators, incomplete models of our robots, building good simulators, learning over sequences of decisions, transferring what we've learned in simulation to real robots, or learning on the robots themselves.
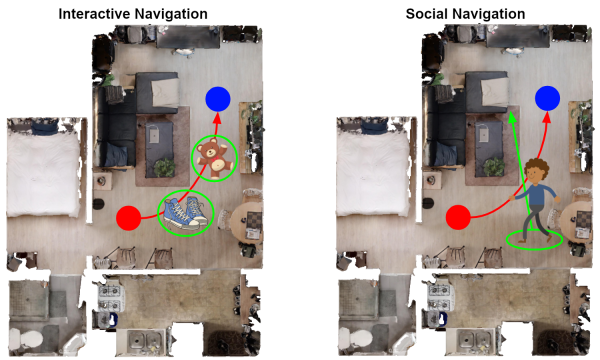
The Embodied AI Workshop brings together many researchers and organizations interested in these problems, and also hosts nine challenges which test point, object, interactive and social navigation, as well as object manipulation, vision, language, auditory perception, mapping, and more. These challenges enable researchers to test their approaches on standardized benchmarks, so the community can more easily compare what we're doing. I'm most involved as an advisor to the Stanford / Google iGibson Interactive / Social Navigation Challenge, which forces robots to maneuver around people and clutter to solve navigation problems. You can read more about the iGibson Challenge at their website or on the Google AI Blog.
Most importantly, the Embodied AI Workshop has a call for papers, with a deadline of TODAY.
Call for Papers
We invite high-quality 2-page extended abstracts in relevant areas, such as:
Simulation Environments
Visual Navigation
Rearrangement
Embodied Question Answering
Simulation-to-Real Transfer
Embodied Vision & Language
Accepted papers will be presented as posters. These papers will be made publicly available in a non-archival format, allowing future submission to archival journals or conferences.
Submission
The submission deadline is May 14th (Anywhere on Earth). Papers should be no longer than 2 pages (excluding references) and styled in the CVPR format. Paper submissions are now open.
I assume anyone submitting to this already has their paper well underway, but this is your reminder to git'r done.
Christianity is a tall ask for many skeptically-minded people, especially if you come from the South, where a lot of folks express Christianity in terms of having a close personal relationship with a person claimed to be invisible, intangible and yet omnipresent, despite having been dead for 2000 years.
On the other hand, I grew up with a fair number of Christians who seem to have no skeptical bones at all, even at the slightest and most explainable of miracles, like my relative who went on a pilgrimage to the Virgin Mary apparitions at Conyers and came back "with their silver rosary having turned to gold."
Or, perhaps - not to be a Doubting Thomas - it was always of a yellowish hue.
Being a Christian isn't just a belief, it's a commitment. Being a Christian is hard, and we're not supposed to throw up stumbling blocks for other believers. So, when I encounter stories like these, which don't sound credible to me and which I don't need to support my faith, I often find myself biting my tongue.
But despite these stories not sounding credible, I do nevertheless admit that they're technically possible. In the words of one comedian, "The Virgin Mary has got the budget for it," and in a world where every observed particle event contains irreducible randomness, God has left Himself the room He needs.
But there's a long tradition in skeptical thought to discount rare events like alleged miracles, rooted in Enlightenment philosopher David Hume's essay "Of Miracles". I almost wrote "scientific thought", but this idea is not at all scientific - it's actually an injection of one of philosophy's worst sins into science.
Philosophy! Who needs it? Well, as Ayn Rand once said: everyone. Philosophy asks the basic questions What is there? (ontology), How do we know it? (epistemology), and What should we do? (ethics). The best philosophy illuminates possibilities for thought and persuasively argues for action.
But philosophy, carving its way through the space of possible ideas, must necessarily operate through arguments, principally verbal arguments which can never conclusively convince. To get traction, we must move beyond argument to repeatable reasoning - mathematics - backed up by real-world evidence.
And that's precisely what was happening right as Hume was working on his essay "Of Miracles" in the 1740's: the laws of probability and chance were being worked out by Hume's contemporaries, some of whom he corresponded with, but he couldn't wait - or couldn't be bothered to learn - their real findings.
I'm not trying to be rude to Hume here, but making a specific point: Hume wrote about evidence, and people claim his arguments are based in rationality - but Hume's arguments are only qualitative, and the quantitative mathematics of probability being developed don't support his idea.
But they can reproduce his idea, and the ideas of the credible believer, in a much sounder framework.
In all fairness, it's best not to be too harsh with Hume, who wrote "Of Miracles" almost twenty years before Reverend Thomas Bayes' "An Essay toward solving a Problem in the Doctrine of Chances," the work which gave us Bayes' Theorem, which became the foundation of modern probability theory.
If the ground is wet, how likely is it that it rained? Intuitively, this depends on how likely it is that the rain would wet the ground, and how likely it is to rain in the first place, discounted by the chance the ground would be wet on its own, say from a sprinkler system.
In Greenville, South Carolina, it rains a lot, wetting the ground, which stays wet because it's humid, and sprinklers don't run all the time, so a wet lawn is a good sign of rain. Ask that question in Death Valley, with rare rain, dry air - and you're watering a lawn? Seriously? - and that calculus changes considerably.
Bayes' Theorem formalizes this intuition. It tells us the probability of an event given the evidence is determined by the likelihood of the evidence given the event, times the probability of the event, divided by the probability of the evidence happening all by its lonesome.
Since Bayes's time, probabilistic reasoning has been considerably refined. In the book Probability Theory: The Logic of Science, E. T. Jaynes, a twentieth-century physicist, shows probabilistic reasoning can explain cognitive "errors," political controversies, skeptical disbelief and credulous believers.
Jaynes's key idea is that for things like commonsense reasoning, political beliefs, and even interpreting miracles, we aren't combining evidence we've collected ourselves in a neat Bayesian framework: we're combining claims provided to us by others - and must now rate the trustworthiness of the claimer.
In our rosary case, the claimer drove down to Georgia to hear a woman speak at a farmhouse. I don't mean to throw up a stumbling block to something that's building up someone else's faith, but when the Bible speaks of a sign not being given to this generation, I feel like its speaking to us today.
But, whether you see the witness as credible or not, Jaynes points out we also weigh alternative explanations. This doesn't affect judging whether a wet lawn means we should bring an umbrella, but when judging a silver rosary turning to gold, there are so many alternatives: lies, delusions, mistakes.
Jaynes shows, with simple math, that when we're judging a claim of a rare event with many alternative explanations, our trust in the claimer that dominates the change in our probabilistic beliefs. If we trust the claimer, we're likely to believe the claim; if we distrust the claimer, we're likely to mistrust the claim.
What's worse, there's a feedback loop between the trust and belief: if we trust someone, and they claim something we come to believe is likely, our trust in them is reinforced; if we distrust someone, and they claim something we come to believe is not likely, our distrust of them is reinforced too.
It shouldn't take a scientist or a mathematician to realize that this pattern is a pathology. Regardless of what we choose to believe, the actual true state of the world is a matter of natural fact. It did or did not rain, regardless of whether the ground is wet; the rosary did or did not change, whether it looks gold.
Ideally, whether you believe in the claimer - your opinions about people - shouldn't affect what you believe about reality - the facts about the world. But of course, it does. This is the real problem with rare events, much less miracles: they're resistant to experiment, which is our normal way out of this dilemma.
Many skeptics argue we should completely exclude the possibility of the supernatural. That's not science, it's just atheism in a trench coat trying to sell you a bad idea. What is scientific, in the words of Newton, is excluding from our scientific hypotheses any causes not necessary or sufficient to explain phenomena.
A one-time event, such as my alleged phone call to my insurance agent today to talk about a policy for my new car, is strictly speaking not a subject for scientific explanation. To analyze the event, it must be in a class of phenomena open to experiments, such as cell phone calls made by me, or some such.
Otherwise, it's just a data point. An anecdote, an outlier. If you disbelieve me - if you check my cell phone records and argue it didn't happen - scientifically, that means nothing. Maybe I used someone else's phone because mine was out of charge. Maybe I misremembered a report of a very real event.
Your beliefs don't matter. I'll still get my insurance card in a couple of weeks.
So-called "supernatural" events, such as the alleged rosary transmutation, fall into this category. You can't experiment on them to resolve your personal bias, so you have to fall back on your trust for the claimer. But that trust is, in a sense, a personal judgment, not a scientific one.
Don't get me wrong: it's perfectly legitimate to exclude "supernatural" events from your scientific theories - I do, for example. We have to: following Newton, for science to work, we must first provide as few causes as possible, with as many far-reaching effects as possible, until experiment says otherwise.
But excluding rare events from our scientific view of the world forecloses the ability of observation to revise our theories. And excluding supernatural events from our broader view of the world is not a requirement of science, but a personal choice - a deliberate choice not to believe.
That may be right. That may be wrong. What happens, happens, and doesn't happen any other way. Whether that includes the possibility of rare events is a matter of natural fact, not personal choice; whether that includes the possibility of miracles is something you have to take on faith.
-the Centaur
Pictured: Allegedly, Thomas Bayes, though many have little faith in the claimants who say this is him.
If you've ever gone to a funeral, watched a televangelist, or been buttonholed by a street preacher, you've probably heard Christianity is all about saving one's immortal soul - by believing in Jesus, accepting the Bible's true teaching on a social taboo, or going to the preacher's church of choice.
(Only the first of these actually works, by the way).
But what the heck is a soul? Most religious people seem convinced that we've got one, some ineffable spiritual thing that isn't destroyed when you die but lives on in the afterlife. Many scientifically minded people have trouble believing in spirits and want to wash their hands of this whole soul idea.
Strangely enough, modern Christian theology doesn't rely too much on the idea of the soul. God exists, of course, and Jesus died for our sins, sending the Holy Spirit to aid us; as for what to do with that information, theology focuses less on what we are and more on what we should believe and do.
If you really dig into it, Christian theology gets almost existential, focusing on us as living beings, present here on the Earth, making decisions and taking consequences. Surprisingly, when we die, our souls don't go to heaven: instead, you're just dead, waiting for the Resurrection and the Final Judgement.
(About that, be not afraid: Jesus, Prince of Peace, is the Judge at the Final Judgment).
This model of Christianity doesn't exclude the idea of the soul, but it isn't really needed: When we die, our decision making stops, defining our relationship to God, which is why it's important to get it right in this life; when it's time for the Resurrection, God has the knowledge and budget to put us back together.
That's right: according to the standard interpretation of the Bible as recorded in the Nicene creed, we're waiting in joyful hope for a bodily resurrection, not souls transported to a purely spiritual Heaven. So if there's no need for a soul in this picture, is there any room for it? What is the idea of the soul good for?
Well, quite a lot, as it turns out.
The theology I'm describing should be familiar to many Episcopals, but it's more properly Catholic, and more specifically, "Thomistic", teachings based on the writings of Saint Thomas Aquinas, a thirteenth-century friar who was recognized - both now and then - as one of the greatest Christian philosophers.
Aquinas was a brilliant man who attempted to reconcile Aristotle's philosophy with Church doctrine. The synthesis he produced was penetratingly brilliant, surprisingly deep, and, at least in part, is documented in books which are packed in boxes in my garage. So, at best, I'm going to riff on Thomas here.
Ultimately, that's for the best. Aquinas's writings predate the scientific revolution, using a scholastic style of argument which by its nature cannot be conclusive, and built on a foundation of topics about the world and human will which have been superseded by scientific findings on physics and psychology.
But the early date of Aquinas's writings affects his theology as well. For example (riffing as best I can without the reference book I want), Aquinas was convinced that the rational human soul necessarily had to be immaterial because it could represent abstract ideas, which are not physical objects.
But now we're good at representing abstract ideas in physical objects. In fact, the history of the past century and a half of mathematics, logic, computation and AI can be viewed as abstracting human thought processes and making them reliable enough to implement in physical machines.
Look, guys - I am not, for one minute, going to get cocky about how much we've actually cracked of the human intellect, much less the soul. Some areas, like cognitive skills acquisition, we've done quite well at; others, like consciousness, are yielding to insights; others, like emotion, are dauntingly intractable.
But it's no longer a logical necessity to posit an intangible basis for the soul, even if practically it turns out to be true. But digging even deeper into Aquinas's notion of a rational soul helps us understand what it is - and why the decisions we make in this life are so important, and even the importance of grace.
The idea of a "form" in Thomistic philosophy doesn't mean shape: riffing again, it means function. The form of a hammer is not its head and handle, but that it can hammer. This is very similar to the modern notion of functionalism in artificial intelligence - the idea that minds are defined by their computations.
Aquinas believed human beings were distinguished from animals by their rational souls, which were a combination of intellect and will. "Intellect" in this context might be described in artificial intelligence terms as supporting a generative knowledge level: the ability to represent essentially arbitrary concepts.
Will, in contrast, is selecting an ideal model of yourself and attempting to guide your actions to follow it. This is a more sophisticated form of decision making than typically used in artificial intelligence; one might describe it as a reinforcement learning agent guided by a self-generated normative model.
What this means, in practice, is that the idea of believing in Jesus and choosing to follow Him isn't simply a good idea: it corresponds directly to the basic functions of the rational soul - intellect, forming an idea of Jesus as a (divinely) good role model, and attempting to follow in His footsteps in our choice of actions.
But the idea of the rational soul being the form of the body isn't just its instantaneous function at one point in time. God exists out of time - and all our thoughts and choices throughout our lives are visible to Him. Our souls are the sum of all of these - making the soul the form of the body over our entire lives.
This means the history of our choices live in God's memory, whether it's helping someone across the street, failing to forgive an irritating relative, going to confession, or taking communion. Even sacraments like baptism that supposedly "leave an indelible spiritual character on the soul" fit in this model.
This model puts the following Jesus, trying to do good and avoid evil, and partaking in sacraments in perspective. God knows what we sincerely believe in our hearts, whether we live up to it or not, and is willing to cut us slack through the mechanisms of worship and grace that add to our permanent record.
Whether souls have a spiritual nature or not - whether they come from the Guf, are joined to our bodies in life, and hang out in Hades after death awaiting reunion at the Resurrection, or whether they simply don't - their character is affected by what we believe, what we do, and how we worship here and now.
And that's why it's important to follow Jesus on this Earth, no matter what happens in the afterlife.
Alan Turing, rendered over my own roughs using several layers of tracing paper. I started with the below rough, in which I tried to pay careful attention to the layout of the face - note the use of the 'third eye' for spacing and curved contour lines - and the relationship of the body, the shoulders and so on.
I then corrected that into the following drawing, trying to correct the position and angles of the eyes and mouth - since I knew from previous drawings that I tended to straighten things that were angled, I looked for those flaws and attempted to correct them. (Still screwed up the hair and some proportions).
This was close enough for me to get started on the rendering. In the end, I like how it came out, even though I flattened the curves of the hair and slightly squeezed the face and pointed the eyes slightly wrong, as you can see if you compare it to the following image from this New Yorker article:
-the Centaur
Lent is when Christians choose to give things up or to take things on to reflect upon the death of Jesus. For Lent, I took on this self-referential series about Lent, arguing Christianity is following Jesus, and that following role models are better than following rules because all sets of rules are ultimately incompete.
But how can we choose to follow Jesus? To many Christians, the answer is simple: "free will." At one Passion play (where I played Jesus, thanks to my long hair), the author put it this way: "You are always choose, because no-one can take your will away. You know that, don't you?"
Christians are highly attached to the idea of free will. However, I know a fair number of atheists and agnostics who seem attached to the idea of free will being a myth. I always find this bit of pseudoscence a bit surprising coming from scientifically minded folk, so it's worth asking the question.
Do we have free will, or not?
Well, it depends on what kind of free will we're talking about. Philosopher Daniel Dennett argues at book length that there are many definitions of "free will", only some varieties of which are worth having. I'm not going to use Dennett's breakdown of free will; I'll use mine, based on discussions with people who care.
The first kind of "free will" is undetermined will: the idea that "I", as consciousness or spirit, can make things happen, outside the control of physical law. Well, fine, if you want to believe that: the science of quantum mechanics allows that, since all observable events have unresolvable randomness.
But the science of quantum mechanics also suggests we could never prove that idea scientifically. To see why, look at entanglement: particles that are observed here are connected to particles over there. Say, if momentum is conserved, and two particles fly apart, if one goes left, the other must go right.
But each observed event is random. You can't predict one from the other; you can only extract it from the record by observing both particles and comparing the results. So if your soul is directing your body's choices, we could only tell by recording all the particles of your body and soul and comparing them.
Good luck with that.
The second kind of "free will" is instantaneous will: the idea that "I", at any instant of time, could have chosen to do something differently. It's unlikely we have this kind of free will. First, according to Einstein, simultaneity has no meaning for physically separated events - like the two hemispheres of your brain.
But, more importantly, the idea of an instant is just that - an idea. Humans are extended over time and space; the brain is fourteen hundred cubic centimeters of goo, making decisions over timescales ranging from a millisecond (a neuron fires) to a second and a half (something novel enters consciousness.)
But, even if you accept that we are physically and temporally extended beings, you may still cling to - or reject - an idea of free will: sovereign will, the idea that our decisions, while happening in our brains and bodies, are nevertheless our own. The evidence is fairly good that we have this kind of free will.
Our brains are physically isolated by our skulls and the blood-brain barrier. While we have reflexes, human decision making happens in the neocortex, which is largely decoupled from direct external responses. Even techniques like persuasion and hypnosis at best have weak, indirect effects.
But breaking our decision-making process down this way sometimes drives people away. It makes religious people cling to the hope of undetermined will; it makes scientific people erroneously think that we don't have free will at all, because our actions are not "ours", but are made by physical processes.
But arguing that "because my decisions are made by physical processes, therefore my decisions are not actually mine" requires the delicate dance of identifying yourself with those processes before the comma, then rejecting them afterwards. Either those decision making processes are part of you, or they are not.
If they're not, please go join the religious folks over in the circle marked "undetermined will."
If they are, then arguing that your decisions are not yours because they're made by ... um, the decision making part of you ... is a muddle of contradictions: a mix of equivocation (changing the meaning of terms) and a category error (mistaking your decision making as something separate from yourself).
But people committed to the non-existence of free will sometimes double down, claiming that even if we accept those decision making processes as part of us, our decisions are somehow not "ours" or not "free" because the outcome of our decision making process is still determined by physical laws.
To someone working on Markov decision processes - decision machines - this seems barely coherent.
The foundation of this idea is sometimes called Laplace's demon - the idea that a creature with perfect knowledge of all physical laws and particles and forces would be able to predict the entire history of the universe - and your decisions, so therefore, they're not your decisions, just the outcome of laws.
Too bad this is impossible. Not practically impossible - literally, mathematically impossible.
To see why, we need to understand the Halting Problem - the seemingly simple question of whether we can build a program to tell if any given computer program will halt given any particular input. As basic as this question sounds, Alan Turing proved in the 1930's that this is mathematically impossible.
The reason is simple: if you could build an analysis program which could solve this problem, you could feed itself to itself - wrapped in a loop that went forever if the original analysis program halts, and halts if it ran forever. No matter what answer it produces, it leads to a contradiction. The program won't work.
This idea seems abstract, but its implications are deep. It applies to not just computer programs, but to a broad class of physical systems in a broad class of universes. And it has corollaries, the most important being: you cannot predict what any arbitrary given algorithm will do without letting the algorithm do it.
If you could, you could use it to predict whether a program would halt, and therefore, you could solve the Halting Problem. That's why Laplace's Demon, as nice a thought experiment as it is, is slain by Turing's Machine. To predict what you would actually do, part of the demon would have to be identical to you.
Nothing else in the universe - nothing else in a broad class of universes - can predict your decisions. Your decisions are made in your own head, not anyone else's, and even though they may be determined by physical processes, the physical processes that determine them are you. Only you can do you.
Yesterday I claimed that Christianity was following Jesus - looking at him as a role model for thinking, judging, and doing, stepping away from rules and towards principles, choosing good outcomes over bad ones and treating others like we wanted to be treated, and ultimately emulating what Jesus would do.
But it's an entirely fair question to ask, why do we need a role model to follow? Why not have a set of rules that guide our behavior, or develop good principles to live by? Well, it turns out it's impossible - not hard, but literally mathematically impossible - to have perfect rules, and principles do not guide actions. So a role model is the best tool we have to help us build the cognitive skill of doing the right thing.
Let's back up a bit. I want to talk about what rules are, and how they differ from principles and models.
In the jargon of my field, artificial intelligence, rules are if-then statements: if this, then do that. They map a range of propositions to a domain of outcomes, which might be actions, new propositions, or edits to our thoughts. There's a lot of evidence that the lower levels of operation of our minds is rule-like.
Principles, in contrast, are descriptions of situations. They don't prescribe what to do; they evaluate what has been done. The venerable artificial intelligence technique of generate-and-test - throw stuff on the wall to see what sticks - depends on "principles" to evaluate whether the outcomes are good.
Models are neither if-then rules nor principles. Models predict the evolution of a situation. Every time you play a computer game, a model predicts how the world will react to your actions. Every time you think to yourself, "I know what my friend would say in response to this", you're using a model.
Rules, of a sort, may underly our thinking, and some of our most important moral precepts are encoded in rules, like the Ten Commandments. But rules are fundamentally limited. No matter how attached you are to any given set of rules, eventually, those rules can fail you, and you can't know when.
The iron laws behind these fatal flaws are Gödel's incompleteness theorems. Back in the 1930's, Kurt Gödel showed any set of rules sophisticated enough to handle basic math would either fail to find things that were true, or would make mistakes - and, worse, could never prove that they were consistent.
Like so many seemingly abstract mathematical concepts, this has practical real-world implications. If you're dealing with anything at all complicated, and try to solve your problems with a set of rules, either those rules will fail to find the right answers, or will give the wrong answers, and you can't tell which.
That's why principles are better than rules: they make no pretensions of being a complete set of if-then rules that can handle all of arithmetic and their own job besides. They evaluate propositions, rather than generating them, they're not vulnerable to the incompleteness result in the same way.
How does this affect the moral teachings of religion? Well, think of it this way: God gave us the Ten Commandments (and much more) in the Old Testament, but these if-then rules needed to be elaborated and refined into a complete system. This was a cottage industry by the time Jesus came on the scene.
Breaking with the rule-based tradition, Jesus gave us principles, such as "love thy neighbor as thyself" and "forgive as you wish to be forgiven" which can be used to evaluate our actions. Sometimes, some thought is required to apply them, as in the case of "Is it lawful to do good or evil on the Sabbath?"
This is where principles fail: they don't generate actions, they merely evaluate them. Some other process needs to generate those actions. It could be a formal set of rules, but then we're back at square Gödel. It could be a random number generator, but an infinite set of monkeys will take forever to cross the street.
This is why Jesus's function as a role model - and the stories about Him in the Bible - are so important to Christianity. Humans generate mental models of other humans all the time. Once you've seen enough examples of someone's behavior, you can predict what they will do, and act and react accordingly.
The stories the Bible tells about Jesus facing moral questions, ethical challenges, physical suffering, and even temptation help us build a model of what Jesus would do. A good model of Jesus is more powerful than any rule and more useful than any principle: it is generative, easy to follow, and always applicable.
Even if you're not a Christian, this model of ethics can help you. No set of rules can be complete and consistent, or even fully checkable: rules lawyering is a dead end. Ethical growth requires moving beyond easy rules to broader principles which can be used to evaluate the outcomes of your choices.
But principles are not a guide to action. That's where role models come in: in a kind of imitation-based learning, they can help guide us by example until we've developed the cognitive skills to make good decisions automatically. Finding role models that you trust can help you grow, and not just morally.
Good role models can help you decide what to do in any situation. Not every question is relevant to the situations Jesus faced in ancient Galilee! For example, when faced with a conundrum, I sometimes ask three questions: "What would Jesus do? What would Richard Feynman do? What would Ayn Rand do?"
These role models seem far apart - Ayn Rand, in particular, tried to put herself on the opposite pole from Jesus. But each brings unique mental thought processes to the table - "Is this doing good or evil?" "You are the easiest person for yourself to fool" and "You cannot fake reality in any way whatsoever."
Jesus helps me focus on what choices are right. Feynman helps me challenge my assumptions and provides methods to test them. Rand is benevolent, but demands that we be honest about reality. If two or three of these role models agree on a course of action, it's probably a good choice.
Jesus was a real person in a distant part of history. We can only reach an understanding of who Jesus is and what He would do by reading the primary source materials about him - the Bible - and by analyses that help put these stories in context, like religious teachings, church tradition, and the use of reason.
But that can help us ask what Jesus would do. Learning the rules are important, and graduating beyond them to understand principles is even more important. But at the end of the day, we want to do the right thing, by following the lead of the man who asks, "Love thy neighbor as thyself."
"Robots in Montreal," eh? Sounds like the title of a Steven Moffat Doctor Who episode. But it's really ICRA 2019 - the IEEE Conference on Robotics and Automation, and, yes, there are quite a few robots!
My team presented our work on evolutionary learning of rewards for deep reinforcement learning, AutoRL, on Monday. In an hour or so, I'll be giving a keynote on "Systematizing Robot Navigation with AutoRL":
Keynote: Dr. Anthony Francis Systematizing Robot Navigation with AutoRL: Evolving Better Policies with Better Evaluation
Abstract: Rigorous scientific evaluation of robot control methods helps the field progress towards better solutions, but deploying methods on robots requires its own kind of rigor. A systematic approach to deployment can do more than just make robots safer, more reliable, and more debuggable; with appropriate machine learning support, it can also improve robot control algorithms themselves. In this talk, we describe our evolutionary reward learning framework AutoRL and our evaluation framework for navigation tasks, and show how improving evaluation of navigation systems can measurably improve the performance of both our evolutionary learner and the navigation policies that it produces. We hope that this starts a conversation about how robotic deployment and scientific advancement can become better mutually reinforcing partners.
Bio: Dr. Anthony G. Francis, Jr. is a Senior Software Engineer at Google Brain Robotics specializing in reinforcement learning for robot navigation. Previously, he worked on emotional long-term memory for robot pets at Georgia Tech's PEPE robot pet project, on models of human memory for information retrieval at Enkia Corporation, and on large-scale metadata search and 3D object visualization at Google. He earned his B.S. (1991), M.S. (1996) and Ph.D. (2000) in Computer Science from Georgia Tech, along with a Certificate in Cognitive Science (1999). He and his colleagues won the ICRA 2018 Best Paper Award for Service Robotics for their paper "PRM-RL: Long-range Robotic Navigation Tasks by Combining Reinforcement Learning and Sampling-based Planning". He's the author of over a dozen peer-reviewed publications and is an inventor on over a half-dozen patents. He's published over a dozen short stories and four novels, including the EPIC eBook Award-winning Frost Moon; his popular writing on robotics includes articles in the books Star Trek Psychology and Westworld Psychology. as well as a Google AI blog article titled Maybe your computer just needs a hug. He lives in San Jose with his wife and cats, but his heart will always belong in Atlanta. You can find out more about his writing at his website.
Hoisted from a recent email exchange with my friend Gordon Shippey:
Re: Whassap?Gordon:
Sounds like a plan.
(That was an actual GMail suggested response. Grumble-grumble AI takeover.)
Anthony:
I<tab-complete> welcome our new robot overlords.
I am constantly amazed by the new autocomplete. While, anecdotally, autocorrect of spell checking is getting worse and worse (I blame the nearly-universal phenomenon of U-shaped development, where a system trying to learn new generalizations gets worse before it gets better), I have written near-complete emails to friends and colleagues with Gmail's suggested responses, and when writing texts to my wife, it knows our shorthand!
One way of doing this back in the day were Markov chain text models, where we learn predictions of what patterns are likely to follow each other; so if I write "love you too boo boo" to my wife enough times, it can predict "boo boo" will follow "love you too" and provide it as a completion. More modern systems use recurrent neural networks to learn richer sets of features with stateful information carried down the chain, enabling modern systems to capture subtler relationships and get better results, as described in the great article "The Unreasonable Effectiveness of Recurrent Neural Networks".
-the<tab-complete> Centaur
So, this happened! Our team's paper on "PRM-RL" - a way to teach robots to navigate their worlds which combines human-designed algorithms that use roadmaps with deep-learned algorithms to control the robot itself - won a best paper award at the ICRA robotics conference!
I talked a little bit about how PRM-RL works in the post "Learning to Drive ... by Learning Where You Can Drive", so I won't go over the whole spiel here - but the basic idea is that we've gotten good at teaching robots to control themselves using a technique called deep reinforcement learning (the RL in PRM-RL) that trains them in simulation, but it's hard to extend this approach to long-range navigation problems in the real world; we overcome this barrier by using a more traditional robotic approach, probabilistic roadmaps (the PRM in PRM-RL), which build maps of where the robot can drive using point to point connections; we combine these maps with the robot simulator and, boom, we have a map of where the robot thinks it can successfully drive.
We were cited not just for this technique, but for testing it extensively in simulation and on two different kinds of robots. I want to thank everyone on the team - especially Sandra Faust for her background in PRMs and for taking point on the idea (and doing all the quadrotor work with Lydia Tapia), for Oscar Ramirez and Marek Fiser for their work on our reinforcement learning framework and simulator, for Kenneth Oslund for his heroic last-minute push to collect the indoor robot navigation data, and to our manager James for his guidance, contributions to the paper and support of our navigation work.
Woohoo! Thanks again everyone!
-the Centaur
When I was a kid (well, a teenager) I'd read puzzle books for pure enjoyment. I'd gotten started with Martin Gardner's mathematical recreation books, but the ones I really liked were Raymond Smullyan's books of logic puzzles. I'd go to Wendy's on my lunch break at Francis Produce, with a little notepad and a book, and chew my way through a few puzzles. I'll admit I often skipped ahead if they got too hard, but I did my best most of the time.
I read more of these as an adult, moving back to the Martin Gardner books. But sometime, about twenty-five years ago (when I was in the thick of grad school) my reading needs completely overwhelmed my reading ability. I'd always carried huge stacks of books home from the library, never finishing all of them, frequently paying late fees, but there was one book in particular - The Emotions by Nico Frijda - which I finished but never followed up on.
Over the intervening years, I did finish books, but read most of them scattershot, picking up what I needed for my creative writing or scientific research. Eventually I started using the tiny little notetabs you see in some books to mark the stuff that I'd written, a "levels of processing" trick to ensure that I was mindfully reading what I wrote.
A few years ago, I admitted that wasn't enough, and consciously began trying to read ahead of what I needed to for work. I chewed through C++ manuals and planning books and was always rewarded a few months later when I'd already read what I needed to to solve my problems. I began focusing on fewer books in depth, finishing more books than I had in years.
Even that wasn't enough, and I began - at last - the re-reading project I'd hoped to do with The Emotions. Recently I did that with Dedekind's Essays on the Theory of Numbers, but now I'm doing it with the Deep Learning. But some of that math is frickin' beyond where I am now, man. Maybe one day I'll get it, but sometimes I've spent weeks tackling a problem I just couldn't get.
Enter puzzles. As it turns out, it's really useful for a scientist to also be a science fiction writer who writes stories about a teenaged mathematical genius! I've had to simulate Cinnamon Frost's staggering intellect for the purpose of writing the Dakota Frost stories, but the further I go, the more I want her to be doing real math. How did I get into math? Puzzles!
So I gave her puzzles. And I decided to return to my old puzzle books, some of the ones I got later but never fully finished, and to give them the deep reading treatment. It's going much slower than I like - I find myself falling victim to the "rule of threes" (you can do a third of what you want to do, often in three times as much time as you expect) - but then I noticed something interesting.
Some of Smullyan's books in particular are thinly disguised math books. In some parts, they're even the same math I have to tackle in my own work. But unlike the other books, these problems are designed to be solved, rather than a reflection of some chunk of reality which may be stubborn; and unlike the other books, these have solutions along with each problem.
So, I've been solving puzzles ... with careful note of how I have been failing to solve puzzles. I've hinted at this before, but understanding how you, personally, usually fail is a powerful technique for debugging your own stuck points. I get sloppy, I drop terms from equations, I misunderstand conditions, I overcomplicate solutions, I grind against problems where I should ask for help, I rabbithole on analytical exploration, and I always underestimate the time it will take for me to make the most basic progress.
Know your weaknesses. Then you can work those weak mental muscles, or work around them to build complementary strengths - the way Richard Feynman would always check over an equation when he was done, looking for those places where he had flipped a sign.
Back to work!
-the Centaur
Pictured: my "stack" at a typical lunch. I'll usually get to one out of three of the things I bring for myself to do. Never can predict which one though.
I often say "I teach robots to learn," but what does that mean, exactly? Well, now that one of the projects that I've worked on has been announced - and I mean, not just on arXiv, the public access scientific repository where all the hottest reinforcement learning papers are shared, but actually, accepted into the ICRA 2018 conference - I can tell you all about it!
When I'm not roaming the corridors hammering infrastructure bugs, I'm trying to teach robots to roam those corridors - a problem we call robot navigation. Our team's latest idea combines "traditional planning," where the robot tries to navigate based on an explicit model of its surroundings, with "reinforcement learning," where the robot learns from feedback on its performance.
For those not in the know, "traditional" robotic planners use structures like graphs to plan routes, much in the same way that a GPS uses a roadmap. One of the more popular methods for long-range planning are probabilistic roadmaps, which build a long-range graph by picking random points and attempting to connect them by a simpler "local planner" that knows how to navigate shorter distances. It's a little like how you learn to drive in your neighborhood - starting from landmarks you know, you navigate to nearby points, gradually building up a map in your head of what connects to what.
But for that to work, you have to know how to drive, and that's where the local planner comes in. Building a local planner is simple in theory - you can write one for a toy world in a few dozen lines of code - but difficult in practice, and making one that works on a real robot is quite the challenge. These software systems are called "navigation stacks" and can contain dozens of components - and in my experience they're hard to get working and even when you do, they're often brittle, requiring many engineer-months to transfer to new domains or even just to new buildings.
People are much more flexible, learning from their mistakes, and the science of making robots learn from their mistakes is reinforcement learning, in which an agent learns a policy for choosing actions by simply trying them, favoring actions that lead to success and suppressing ones that lead to failure. Our team built a deep reinforcement learning approach to local planning, using a state-of-the art algorithm called DDPG (Deep Deterministic Policy Gradients) pioneered by DeepMind to learn a navigation system that could successfully travel several meters in office-like environments.
But there's a further wrinkle: the so-called "reality gap". By necessity, the local planner used by a probablistic roadmap is simulated - attempting to connect points on a map. That simulated local planner isn't identical to the real-world navigation stack running on the robot, so sometimes the robot thinks it can go somewhere on a map which it can't navigate safely in the real world. This can have disastrous consequences - causing robots to tumble down stairs, or, worse, when people follow their GPSes too closely without looking where they're going, causing cars to tumble off the end of a bridge.
Our approach, PRM-RL, directly combats the reality gap by combining probabilistic roadmaps with deep reinforcement learning. By necessity, reinforcement learning navigation systems are trained in simulation and tested in the real world. PRM-RL uses a deep reinforcement learning system as both the probabilistic roadmap's local planner and the robot's navigation system. Because links are added to the roadmap only if the reinforcement learning local controller can traverse them, the agent has a better chance of attempting to execute its plans in the real world.
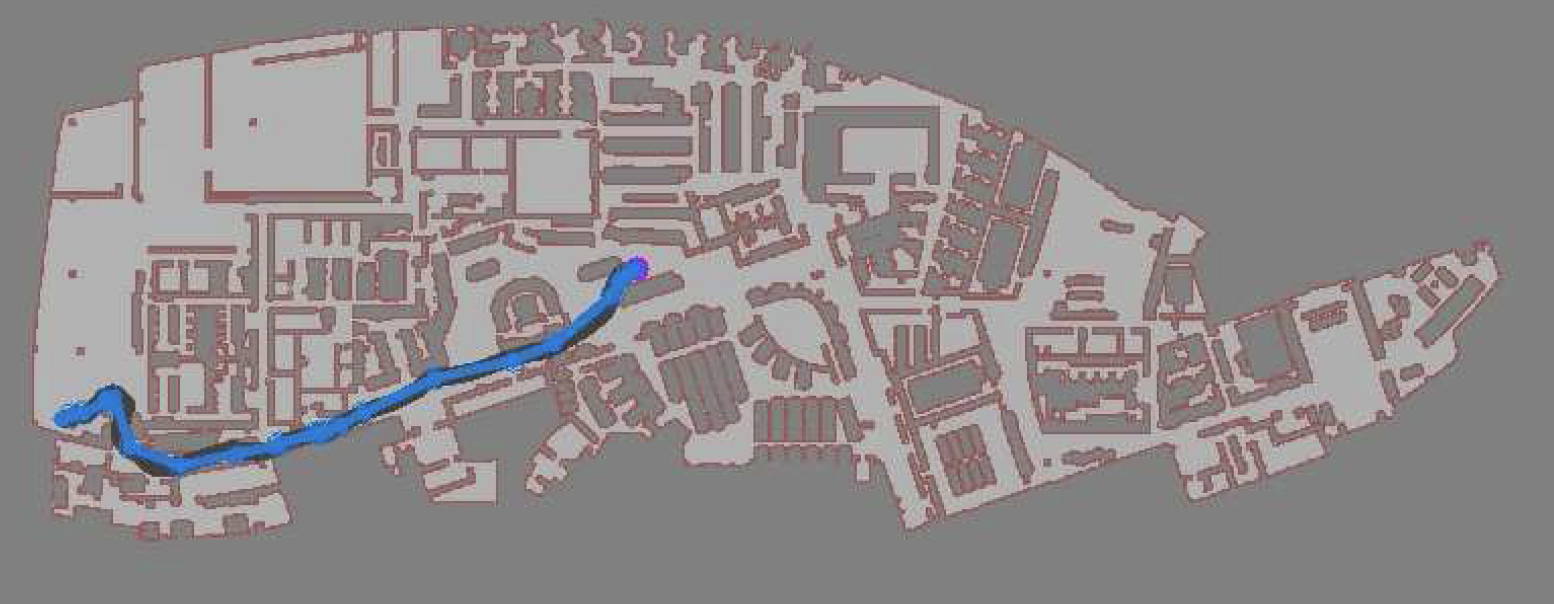
In simulation, our agent could traverse hundreds of meters using the PRM-RL approach, doing much better than a "straight-line" local planner which was our default alternative. While I didn't happen to have in my back pocket a hundred-meter-wide building instrumented with a mocap rig for our experiments, we were able to test a real robot on a smaller rig and showed that it worked well (no pictures, but you can see the map and the actual trajectories below; while the robot's behavior wasn't as good as we hoped, we debugged that to a networking issue that was adding a delay to commands sent to the robot, and not in our code itself; we'll fix this in a subsequent round).
This work includes both our group working on office robot navigation - including Alexandra Faust, Oscar Ramirez, Marek Fiser, Kenneth Oslund, me, and James Davidson - and Alexandra's collaborator Lydia Tapia, with whom she worked on the aerial navigation also reported in the paper. Until the ICRA version comes out, you can find the preliminary version on arXiv:
https://arxiv.org/abs/1710.03937
PRM-RL: Long-range Robotic Navigation Tasks by Combining Reinforcement Learning and Sampling-based Planning
We present PRM-RL, a hierarchical method for long-range navigation task completion that combines sampling-based path planning with reinforcement learning (RL) agents. The RL agents learn short-range, point-to-point navigation policies that capture robot dynamics and task constraints without knowledge of the large-scale topology, while the sampling-based planners provide an approximate map of the space of possible configurations of the robot from which collision-free trajectories feasible for the RL agents can be identified. The same RL agents are used to control the robot under the direction of the planning, enabling long-range navigation. We use the Probabilistic Roadmaps (PRMs) for the sampling-based planner. The RL agents are constructed using feature-based and deep neural net policies in continuous state and action spaces. We evaluate PRM-RL on two navigation tasks with non-trivial robot dynamics: end-to-end differential drive indoor navigation in office environments, and aerial cargo delivery in urban environments with load displacement constraints. These evaluations included both simulated environments and on-robot tests. Our results show improvement in navigation task completion over both RL agents on their own and traditional sampling-based planners. In the indoor navigation task, PRM-RL successfully completes up to 215 meters long trajectories under noisy sensor conditions, and the aerial cargo delivery completes flights over 1000 meters without violating the task constraints in an environment 63 million times larger than used in training.
So, when I say "I teach robots to learn" ... that's what I do.
-the Centaur
So at Dragon Con I had a reading this year. Yeah, looks like this is the last year I get to bring all my books - too many, to heavy! I read the two flash fiction pieces in Jagged Fragments, "If Looks Could Kill" and "The Secret of the T-Rex's Arms", as well as reading the first chapter of Jeremiah Willstone and the Clockwork Time Machine, a bit of my and Jim Davies' essay on the psychology of Star Trek's artificial intelligences, and even a bit of my very first published story, "Sibling Rivalry". I also gave the presentation I was supposed to give at the SAM Talks before I realized I was double booked; that was "Risk Getting Worse".
But that wasn't recorded, so, oh dang, you'll have to either go to my Amazon page to get my books, or wait until we get "Risk Getting Worse" recorded. But my interview with Nancy Northcott for the Daily Dragon, "Robots, Computers, and Magic", however, IS online, so I can share it with you all. Even more so, I want to share what I think is the most important part of my interview:
DD: Do you have any one bit of advice for aspiring writers?AF: Write. Just write. Don’t worry about perfection, or getting published, or even about pleasing anyone else: just write. Write to the end of what you start, and only then worry about what to do with it. In fact, don’t even worry about finishing everything—don’t be afraid to try anything. Artists know they need to fill a sketchbook before sitting down to create a masterwork, but writers sometimes get trapped trying to polish their first inspiration into a final product.
Don’t get trapped on the first hill! Whip out your notebook and write. Write morning pages. Write diary at the end of the day. Write a thousand starts to stories, and if one takes flight, run with it with all the abandon you have in you. Accept all writing, especially your own. Just write. Write.
That's it. To read more, check out the interview here, or see all my Daily Dragon mentions at Dragon Con here, or check out my interviewer Nancy Northcott's site here. Onward!
-the Centaur
Simply put, "artificial intelligence” is people trying to make things do things that we’d call smart if done by people.
So what’s the big deal about that?
Well, as it turns out, a lot of people get quite wound up with the definition of "artificial intelligence.” Sometimes this is because they’re invested in a prescientific notion that machines can’t be intelligent and want to define it in a way that writes the field off before it gets started, or it’s because they’re invested in an unscientific degree into their particular theory of intelligence and want to define it in a way that constrains the field to look at only the things they care about, or because they’re actually not scientific at all and want to proscribe the field to work on the practical problems of particular interest to them.
No, I’m not bitter about having to wade through a dozen bad definitions of artificial intelligence as part of a survey. Why do you ask?
Welcome to the future, ladies and gentlemen. Here in the future, the obscure television shows of my childhood rate an entire section in the local bookstore, which combines books, games, music, movies, and even vinyl records with a coffeehouse and restaurant.
Here in the future, the heretofore unknown secrets of my discipline, artificial intelligence, are now conveniently compiled in compelling textbooks that you can peruse at your leisure over a cup of coffee.
Here in the future, genre television shows play on the monitors of my favorite bar / restaurant, and the servers and I have meaningful conversations about the impact of robotics on the future of labor.
And here in the future, Monty Python has taken over the world.
Yep, that’s Python consuming almost 300% of my CPU - guess what, I guess that means this machine has four processing cores, since I saw it hit over 300% - running the TensorFlow tutorial. For those that don’t know, "deep learning” is a relatively recent type of learning which uses improvements in both processing power and learning algorithms to train learning networks that can have dozens or hundreds of layers - sometimes as many layers as neural networks in the 1980’s and 1990’s had nodes.
For those that don’t know even that, neural networks are graphs of simple nodes that mimic brain structures, and you can train them with data that contains both the question and the answer. With enough internal layers, neural networks can learn almost anything, but they require a lot of training data and a lot of computing power. Well, now we’ve got lots and lots of data, and with more computing power, you’d expect we’d be able to train larger networks - but the first real trick was discovering mathematical tricks that keep the learning signal strong deep, deep within the networks.
The second real trick was wrapping all this amazing code in a clean software architecture that enables anyone to run the software anywhere. TensorFlow is one of the most recent of these frameworks - it’s Google’s attempt to package up the deep learning technology it uses internally so that everyone in the world can use it - and it’s open source, so you can download and install it on most computers and try out the tutorial at home. The CPU-baking example you see running here, however, is not the simpler tutorial, but a test program that runs a full deep neural network. Let’s see how it did:
Well. 99.2% correct, it seems. Not bad for a couple hundred lines of code, half of which is loading the test data - and yeah, that program depends on 200+ files worth of Python that the TensorFlow installation loaded onto my MacBook Air, not to mention all the libraries that the TensorFlow Python installation depends on in turn …
But I still loaded it onto a MacBook Air, and it ran perfectly.
Amazing what you can do with computers these days.
-the Centaur




 Alan Turing, rendered over my own roughs using several layers of tracing paper. I started with the below rough, in which I tried to pay careful attention to the layout of the face - note the use of the 'third eye' for spacing and curved contour lines - and the relationship of the body, the shoulders and so on.
Alan Turing, rendered over my own roughs using several layers of tracing paper. I started with the below rough, in which I tried to pay careful attention to the layout of the face - note the use of the 'third eye' for spacing and curved contour lines - and the relationship of the body, the shoulders and so on.
 I then corrected that into the following drawing, trying to correct the position and angles of the eyes and mouth - since I knew from previous drawings that I tended to straighten things that were angled, I looked for those flaws and attempted to correct them. (Still screwed up the hair and some proportions).
I then corrected that into the following drawing, trying to correct the position and angles of the eyes and mouth - since I knew from previous drawings that I tended to straighten things that were angled, I looked for those flaws and attempted to correct them. (Still screwed up the hair and some proportions).
 This was close enough for me to get started on the rendering. In the end, I like how it came out, even though I flattened the curves of the hair and slightly squeezed the face and pointed the eyes slightly wrong, as you can see if you compare it to the following image from
This was close enough for me to get started on the rendering. In the end, I like how it came out, even though I flattened the curves of the hair and slightly squeezed the face and pointed the eyes slightly wrong, as you can see if you compare it to the following image from  -the Centaur
-the Centaur 








 So, this happened! Our team's paper on "PRM-RL" - a way to teach robots to navigate their worlds which combines human-designed algorithms that use roadmaps with deep-learned algorithms to control the robot itself - won a best paper award at the ICRA robotics conference!
So, this happened! Our team's paper on "PRM-RL" - a way to teach robots to navigate their worlds which combines human-designed algorithms that use roadmaps with deep-learned algorithms to control the robot itself - won a best paper award at the ICRA robotics conference!
 I talked a little bit about how PRM-RL works in the post "
I talked a little bit about how PRM-RL works in the post " We were cited not just for this technique, but for testing it extensively in simulation and on two different kinds of robots. I want to thank everyone on the team - especially Sandra Faust for her background in PRMs and for taking point on the idea (and doing all the quadrotor work with Lydia Tapia), for Oscar Ramirez and Marek Fiser for their work on our reinforcement learning framework and simulator, for Kenneth Oslund for his heroic last-minute push to collect the indoor robot navigation data, and to our manager James for his guidance, contributions to the paper and support of our navigation work.
We were cited not just for this technique, but for testing it extensively in simulation and on two different kinds of robots. I want to thank everyone on the team - especially Sandra Faust for her background in PRMs and for taking point on the idea (and doing all the quadrotor work with Lydia Tapia), for Oscar Ramirez and Marek Fiser for their work on our reinforcement learning framework and simulator, for Kenneth Oslund for his heroic last-minute push to collect the indoor robot navigation data, and to our manager James for his guidance, contributions to the paper and support of our navigation work.
 Woohoo! Thanks again everyone!
-the Centaur
Woohoo! Thanks again everyone!
-the Centaur  When I was a kid (well, a teenager) I'd read puzzle books for pure enjoyment. I'd gotten started with Martin Gardner's mathematical recreation books, but the ones I really liked were Raymond Smullyan's books of logic puzzles. I'd go to Wendy's on my lunch break at Francis Produce, with a little notepad and a book, and chew my way through a few puzzles. I'll admit I often skipped ahead if they got too hard, but I did my best most of the time.
I read more of these as an adult, moving back to the Martin Gardner books. But sometime, about twenty-five years ago (when I was in the thick of grad school) my reading needs completely overwhelmed my reading ability. I'd always carried huge stacks of books home from the library, never finishing all of them, frequently paying late fees, but there was one book in particular - The Emotions by Nico Frijda - which I finished but never followed up on.
Over the intervening years, I did finish books, but read most of them scattershot, picking up what I needed for my creative writing or scientific research. Eventually I started using the tiny little notetabs you see in some books to mark the stuff that I'd written, a "levels of processing" trick to ensure that I was mindfully reading what I wrote.
A few years ago, I admitted that wasn't enough, and consciously began trying to read ahead of what I needed to for work. I chewed through C++ manuals and planning books and was always rewarded a few months later when I'd already read what I needed to to solve my problems. I began focusing on fewer books in depth, finishing more books than I had in years.
Even that wasn't enough, and I began - at last - the re-reading project I'd hoped to do with The Emotions. Recently I did that with Dedekind's Essays on the Theory of Numbers, but now I'm doing it with the Deep Learning. But some of that math is frickin' beyond where I am now, man. Maybe one day I'll get it, but sometimes I've spent weeks tackling a problem I just couldn't get.
Enter puzzles. As it turns out, it's really useful for a scientist to also be a science fiction writer who writes stories about a teenaged mathematical genius! I've had to simulate Cinnamon Frost's staggering intellect for the purpose of writing the Dakota Frost stories, but the further I go, the more I want her to be doing real math. How did I get into math? Puzzles!
So I gave her puzzles. And I decided to return to my old puzzle books, some of the ones I got later but never fully finished, and to give them the deep reading treatment. It's going much slower than I like - I find myself falling victim to the "rule of threes" (you can do a third of what you want to do, often in three times as much time as you expect) - but then I noticed something interesting.
Some of Smullyan's books in particular are thinly disguised math books. In some parts, they're even the same math I have to tackle in my own work. But unlike the other books, these problems are designed to be solved, rather than a reflection of some chunk of reality which may be stubborn; and unlike the other books, these have solutions along with each problem.
So, I've been solving puzzles ... with careful note of how I have been failing to solve puzzles. I've hinted at this before, but understanding how you, personally, usually fail is a powerful technique for debugging your own stuck points. I get sloppy, I drop terms from equations, I misunderstand conditions, I overcomplicate solutions, I grind against problems where I should ask for help, I rabbithole on analytical exploration, and I always underestimate the time it will take for me to make the most basic progress.
Know your weaknesses. Then you can work those weak mental muscles, or work around them to build complementary strengths - the way Richard Feynman would always check over an equation when he was done, looking for those places where he had flipped a sign.
Back to work!
-the Centaur
Pictured: my "stack" at a typical lunch. I'll usually get to one out of three of the things I bring for myself to do. Never can predict which one though.
When I was a kid (well, a teenager) I'd read puzzle books for pure enjoyment. I'd gotten started with Martin Gardner's mathematical recreation books, but the ones I really liked were Raymond Smullyan's books of logic puzzles. I'd go to Wendy's on my lunch break at Francis Produce, with a little notepad and a book, and chew my way through a few puzzles. I'll admit I often skipped ahead if they got too hard, but I did my best most of the time.
I read more of these as an adult, moving back to the Martin Gardner books. But sometime, about twenty-five years ago (when I was in the thick of grad school) my reading needs completely overwhelmed my reading ability. I'd always carried huge stacks of books home from the library, never finishing all of them, frequently paying late fees, but there was one book in particular - The Emotions by Nico Frijda - which I finished but never followed up on.
Over the intervening years, I did finish books, but read most of them scattershot, picking up what I needed for my creative writing or scientific research. Eventually I started using the tiny little notetabs you see in some books to mark the stuff that I'd written, a "levels of processing" trick to ensure that I was mindfully reading what I wrote.
A few years ago, I admitted that wasn't enough, and consciously began trying to read ahead of what I needed to for work. I chewed through C++ manuals and planning books and was always rewarded a few months later when I'd already read what I needed to to solve my problems. I began focusing on fewer books in depth, finishing more books than I had in years.
Even that wasn't enough, and I began - at last - the re-reading project I'd hoped to do with The Emotions. Recently I did that with Dedekind's Essays on the Theory of Numbers, but now I'm doing it with the Deep Learning. But some of that math is frickin' beyond where I am now, man. Maybe one day I'll get it, but sometimes I've spent weeks tackling a problem I just couldn't get.
Enter puzzles. As it turns out, it's really useful for a scientist to also be a science fiction writer who writes stories about a teenaged mathematical genius! I've had to simulate Cinnamon Frost's staggering intellect for the purpose of writing the Dakota Frost stories, but the further I go, the more I want her to be doing real math. How did I get into math? Puzzles!
So I gave her puzzles. And I decided to return to my old puzzle books, some of the ones I got later but never fully finished, and to give them the deep reading treatment. It's going much slower than I like - I find myself falling victim to the "rule of threes" (you can do a third of what you want to do, often in three times as much time as you expect) - but then I noticed something interesting.
Some of Smullyan's books in particular are thinly disguised math books. In some parts, they're even the same math I have to tackle in my own work. But unlike the other books, these problems are designed to be solved, rather than a reflection of some chunk of reality which may be stubborn; and unlike the other books, these have solutions along with each problem.
So, I've been solving puzzles ... with careful note of how I have been failing to solve puzzles. I've hinted at this before, but understanding how you, personally, usually fail is a powerful technique for debugging your own stuck points. I get sloppy, I drop terms from equations, I misunderstand conditions, I overcomplicate solutions, I grind against problems where I should ask for help, I rabbithole on analytical exploration, and I always underestimate the time it will take for me to make the most basic progress.
Know your weaknesses. Then you can work those weak mental muscles, or work around them to build complementary strengths - the way Richard Feynman would always check over an equation when he was done, looking for those places where he had flipped a sign.
Back to work!
-the Centaur
Pictured: my "stack" at a typical lunch. I'll usually get to one out of three of the things I bring for myself to do. Never can predict which one though.  I often say "I teach robots to learn," but what does that mean, exactly? Well, now that one of the projects that I've worked on has been announced - and I mean, not just on
I often say "I teach robots to learn," but what does that mean, exactly? Well, now that one of the projects that I've worked on has been announced - and I mean, not just on 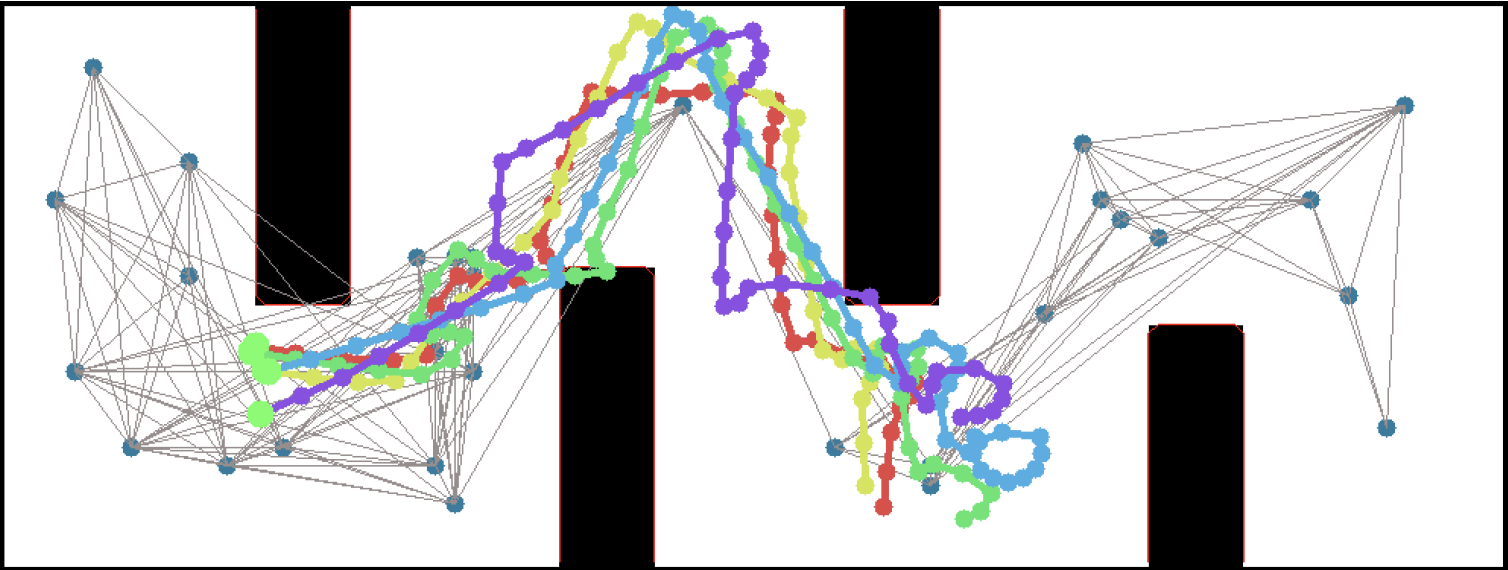 This work includes both our group working on office robot navigation - including Alexandra Faust, Oscar Ramirez, Marek Fiser, Kenneth Oslund, me, and James Davidson - and Alexandra's collaborator Lydia Tapia, with whom she worked on the aerial navigation also reported in the paper. Until the ICRA version comes out, you can find the preliminary version on arXiv:
This work includes both our group working on office robot navigation - including Alexandra Faust, Oscar Ramirez, Marek Fiser, Kenneth Oslund, me, and James Davidson - and Alexandra's collaborator Lydia Tapia, with whom she worked on the aerial navigation also reported in the paper. Until the ICRA version comes out, you can find the preliminary version on arXiv:


 So at Dragon Con I had a reading this year. Yeah, looks like this is the last year I get to bring all my books - too many, to heavy! I read the two flash fiction pieces in
So at Dragon Con I had a reading this year. Yeah, looks like this is the last year I get to bring all my books - too many, to heavy! I read the two flash fiction pieces in  But that wasn't recorded, so, oh dang, you'll have to either go to
But that wasn't recorded, so, oh dang, you'll have to either go to 





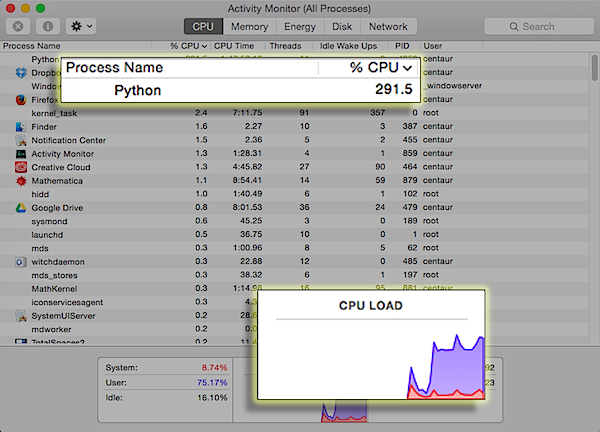 Yep, that’s Python consuming almost 300% of my CPU - guess what, I guess that means this machine has four processing cores, since I saw it hit over 300% - running the
Yep, that’s Python consuming almost 300% of my CPU - guess what, I guess that means this machine has four processing cores, since I saw it hit over 300% - running the 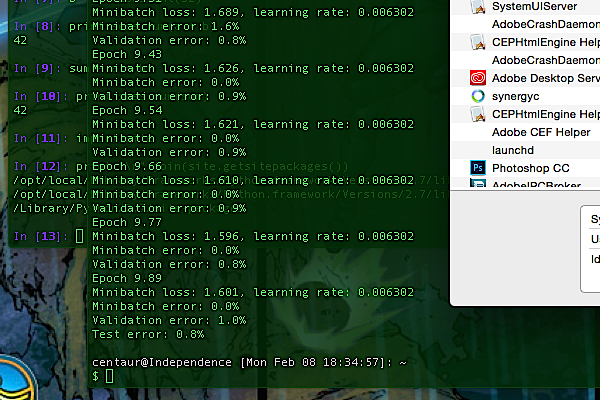 Well. 99.2% correct, it seems. Not bad for a
Well. 99.2% correct, it seems. Not bad for a