So I want to blog more, ideally approaching one a day. If I was just tossing up blog entries for filler, like I sometimes do, that wouldn't be a problem; however, I'd like to put up more substantive articles. But I find that putting up more substantive articles takes a lot of time - so keep up the pace I need to improve my process.
I already have trained myself to use Blogger more efficiently, use tools like Qumana to make it easier to access Blogger while offline, and am experimenting with AndroBlogger in an attempt to make it easy to post while, well, anywhere I've got my Nexus One. But there are still barriers to putting up entries.
One barrier is my process. Note the last paragraph? It has four links. I like to put in links to topics I reference, so a certain amount of time is taken up finding appropriate web pages and linking them in. There isn't much I can do about this except not go down the rabbit hole - ideally, I'd like to post a short paragraph about each link, but that's too much detail.
Another barrier are my goals. One of my friends, Jim Davies, thinks that blog posts should have pictures - and I agree, though I can't immediately find the blog post in which he said it - perhaps that means we discussed it aloud. So ANYWAY, there was another chunk of time wasted trying to find a link. Where was I? Ah. The barriers of my goals.
If I want to blog an article with a picture, the picture needs to be on the web. But I try to avoid linked images for copyright reasons (and to prevent brittleness in case the target takes it down; for embedded Youtubes, which, well, there isn't a good substitute for yet). So I need to upload the image to MY site, a chore I currently do with the Cyberduck ftp client.
And here the constraints get harder: in precisely the same way I don't let iTunes tell me where to put songs, I choose not to use Blogger's interface because I have scheme for posting images which predates Blogger and which I will continue to use after Blogger is gone: http://www.dresan.com/images/imagename.jpg, which is simple and easy to remember.
What's worse, my cameras take images at huge resolutions, so I need to shrink and resize the images to fit in the width that fits on my website. For a variety of reasons, I go with 800x600 or 600x800, in a standard block of HTML which shrinks the image, adds a link to the source of the image, and ads some alt text.
So now I've put on myself a huge set of constraints which makes the simple task of putting up images on my website a chore - get the picture, resize it, start Cyberduck, upload it, write the two lines of HTML gloop necessary to display it, and then and only then see the preview so I can see I made a mistake. There has to be a better way.

Enter UNIX shell scripting, Python and the ImageMagick toolkit.
The first thing that I did to make my life easier was to auto-generate the stanza of text that displays the image. I mean, it's the same thing each time - an anchor tag pointing to the image, with alt text, then the img tag itself, with the same alt text, sizing and border information, like this:
![some alt text]()
src="https://www.dresan.com/images/image.jpg" />
So why write ALL of that every time? Why not just write the changes and let the computer do it for you? SO I wrote a piece of code in Python which does just that, produces that text for me:
#!/usr/bin/python
import sys
TEXT= """

"""
if len(sys.argv) < 3:
print "usage: %s image alt text" % sys.argv[0]
else:
image = "http://www.dresan.com/images/%s" % sys.argv[1]
alt = ' '.join(sys.argv[2:])
print TEXT % (image, alt, image, alt)
I'm not going to turn this into a Python tutorial, so, briefly, all this does is check to make sure I specify a filename and some alt text, stuffs it into a template, and prints it out so I can cut and paste. Here's an example of that in operation, turning chihuly.jpg and "chihuly art at palo alto medical foundation" into a stanza of HTML (spaces added for readability):
centaur@Deliverance (Wed Jan 13, 22:48:25) [520] ~/Development/Workspace/Webworks:
$ ./imagelink.py chihuly.jpg chihuly art at palo alto medical foundation
![]()
alt="chihuly art at palo alto medical foundation"
src="https://www.dresan.com/images/chihuly.jpg" />
That saves me several minutes of typing each time. This is one of the great Programmer's Virtues: laziness - making the computer do something you don't want to do for yourself. The maybe thirty minutes I've spent tweaking that little script have paid off not just in the time that I saved typing, but in the extra blog posts that I've done because they were easier to do.
In the next installment (or two, depending), I'll write a tool to shrink the images to size with ImageMagick and upload them automatically with UNIX tools, and discuss some of the other tools and organization schemes I use which make it easier for me to collect the images and keep them organized - schemes that work even if you switch between operating systems.
-the Centaur

The images are Chihuly glass sculptures hanging in the Mountain View campus of the Palo Alto Medical Foundation.
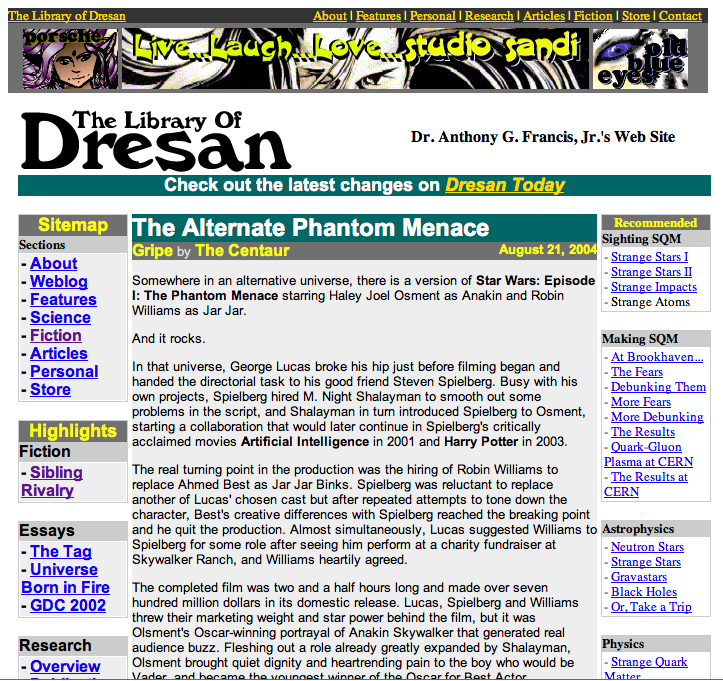
 Amazing, yes, the frames, the under construction sign, the 'bouncer look' photo, etc.
What amazes me even more? It's still up, as of 2010-07-16. Wow.
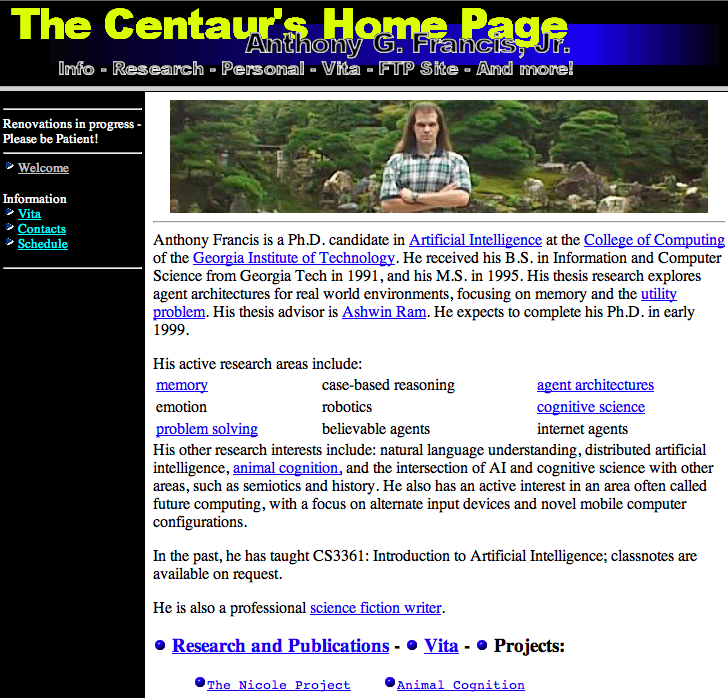
But wait! This just in ... according to the Wayback Machine, this wasn't even the first version of the page; this is the first version of my home page:
Amazing, yes, the frames, the under construction sign, the 'bouncer look' photo, etc.
What amazes me even more? It's still up, as of 2010-07-16. Wow.
But wait! This just in ... according to the Wayback Machine, this wasn't even the first version of the page; this is the first version of my home page:
 Actually I can tell this isn't the actual first version of my page - there are some links missing from it that were in the very earliest version of the page, and it has frames, which I don't think were in the very first page I put up - but this is the oldest recorded version, from almost 14 years ago. Aeons in Internet time ... especially considering the very first web page was only six years earlier, about 20 years ago:
Actually I can tell this isn't the actual first version of my page - there are some links missing from it that were in the very earliest version of the page, and it has frames, which I don't think were in the very first page I put up - but this is the oldest recorded version, from almost 14 years ago. Aeons in Internet time ... especially considering the very first web page was only six years earlier, about 20 years ago:
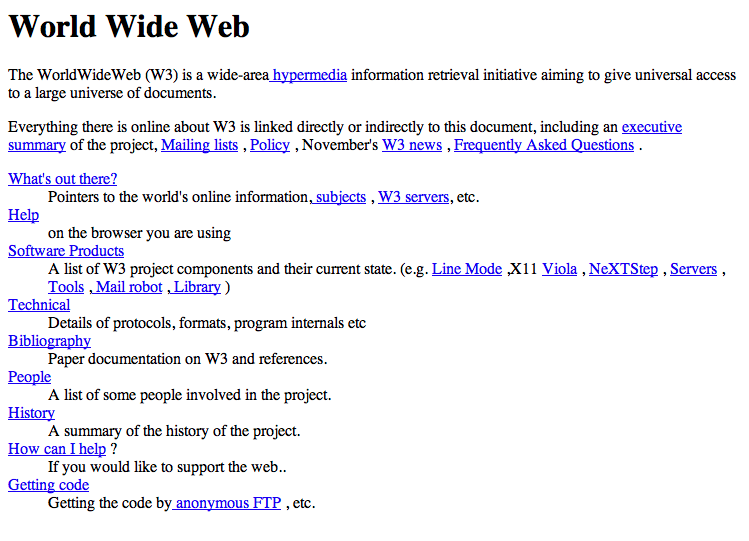 How things have changed in two short decades.
-the Centaur
How things have changed in two short decades.
-the Centaur