
So I wasn't kidding about the long slog: I am still chewing through the classic textbook Pattern Recognition and Machine Learning (PDF) by Christopher Bishop, day and night, even though he's got a newer book out. This is in part because I'm almost done, and in part because his newer book focuses on the foundations of deep learning and is "almost entirely non-Bayesian" - and it's Bayesian theory I'm trying to understand.
This, I think, is part of the discovery I've made recently about "deep learning" - by which I mean learning in depth by people, as opposed to deep learning by machines: hard concepts are by definition tough nuts to crack, and to really understand them, you need to hit them coming and going - to break apart the concept in as many ways as possible to ensure you can take it apart and put it back together again. As Marvin Minsky once said, "You don't understand anything until you learn it more than one way."
To some people, that idea is intuitive; to others, it is easy to dismiss. But if you think about it, when you're learning a subject you don't know, it's like going in blind. And like the parable of the blind men and the elephant - each of whom touched one part of an elephant and assumed they understood the whole - if you dig deeply into a narrow view of a subject, you can get a distorted view, like extrapolating a giant snake from an elephant's trunk, or a tall tree from its leg, or a wide fan from its ear, or a long rope from its tail.
Acting as if those bad assumptions were true could easily get you stomped on - or skewered, by the elephant's tusk, which is sharp like a spear.
So back to Bayesian theory. Now, what the hell is a "Bayes," some of you may ask? (Why are you reviewing the obvious, others of you may snark). Look, we take chances every day, don't we? And we blame ourselves for making a mistake if we know that something is risky, but not so much if we don't know what we don't know - even though we intuitively know that the underlying chances aren't affected by what we know. Well, Thomas Bayes not only understood that, he built a framework to put that on a solid mathematical footing.
Some people think that Bayes' work on probability was trying to refute Hume's argument against miracles, though that connection is disputed (pdf). But the big dispute that arose was between "frequentists" who want to reduce probability to statistics, and "Bayesians" who represent probability as a statement of beliefs. Frequentists incorrectly argued that Bayesian theory was somehow "subjective", and tried to replace Bayesian reasoning with statistical analyses of imaginary projections of existing data out to idealized collections of objects which don't exist. Bayesians, in contrast, recognize that Bayes' Theorem is, well, a theorem, and we can use it to make objective statements of the predictions we can make over different statements of belief - statements which are often hidden in frequentist theory as unstated assumptions.
Now, I snark a bit about frequentist theory there - and not just because the most extreme statements of frequentist theory are objectively wrong, but because some frequentist mathematicians around the first half of the twentieth century engaged in some really shitty behavior which set mathematical progress back decades - but even the arch-Bayesian, E. T. Jaynes, retreated from his dislike of frequentist theory. In his perspective, frequentist methods are how we check the outcome of Bayesian work, and Bayesian theory is how we justify and prove the mathematical structure of frequentist methods. They're a synergy of approaches, and I use frequentism and the tools of frequentists in my research, um, frequently.
But my point, and I did have one, is that even something I thought I understood well is something that I could learn more about. Case in point was not, originally, what I learned about frequentism and Bayesianism a while back; it was what I learned about principal component analysis (PCA) at the session where I took the picture. (I was about to write "last night", but, even though this is a "blogging every day" post, due to me getting interrupted when I was trying to post, this was a few days ago).
PCA is another one of those fancy math terms for a simple idea: you can improve your understanding by figuring out what you should focus on. Imagine you're firing cannon, and you want to figure out where the cannonballs are going to land. There are all sorts of factors that affect this: the direction of the wind, the presence of rain, even thermal noise in the cannon if you wanted to be super precise. But the most important variables in figuring out where the cannonball is going to land is where you're aiming the thing! Unless you're standing on Larry Niven's We Made It in the windy season, you should be far more worried about where the cannon is pointed than the way the wind blows.
PCA is a mathematical tool to help you figure that out by reducing a vast number of variables down to just a small number - usually two or three dimensions so humans can literally visualize it on a graph or in a tank. And PCA has an elegant mathematical formalism in terms of vectors and matrix math which is taught in schools. But it turns out there's an even more elegant Bayesian formalism which models PCA as a process based on "latent" variables, which you can think about as the underlying process behind the variables we observe - using our cannonball example, that process is again "where they're aiming the thing," even if we ultimately just observe where the cannonballs land.
Bayesian PCA is equivalent (you can recover the original PCA formalism from it easily) and elegant (it provides a natural explanation of the dimensions PCA finds as the largest sources of variance) and extensible (you can easily adapt the number of dimensions to the data) and efficient (if you know you just want a few dimensions, you can approximate it with something called the expectation-maximization algorithm, which is way more efficient than the matrix alternative). All that is well and good.
But I don't think I could have even really understood all that if I hadn't already seen PCA in half a dozen other textbooks. The technique is so useful, and demonstrations about it are so illuminating, that I felt I had seen it before - so when Bishop cracked open his Bayesian formulation, I didn't feel like I was just reading line noise. Because, let me tell you, the first time I read a statistical proof, it often feels like line noise.
But this time, I didn't feel that way.
I often try to tackle new problems by digging deep into one book at a time. And I've certainly learned from doing that. But often, after you slog through a whole textbook, it's hard to keep everything you've learned in your head (especially if you don't have several spare weeks to work through all the end-of-chapter exercises, which is a situation I find myself in more often than not).
But more recently I have found going through books in parallel has really helped me. Concepts that one book flies over are dealt with deeply in another. Concepts that another book provides one angle on are tackled from a completely different one in another. Sometimes the meaning and value of concepts are different between different authors. Even intro books sometimes provide crucial perspective that helps you understand some other, deeper text.
So if you're digging into something difficult ... don't try to go it alone. When you reach a tough part, don't give up, search out other references to help you. At first it may seem an impossible nut to crack, but someone, somewhere, may have found the words that will help you understand.
-the Centaur
Pictured: Again Bishop, and again pound cake.










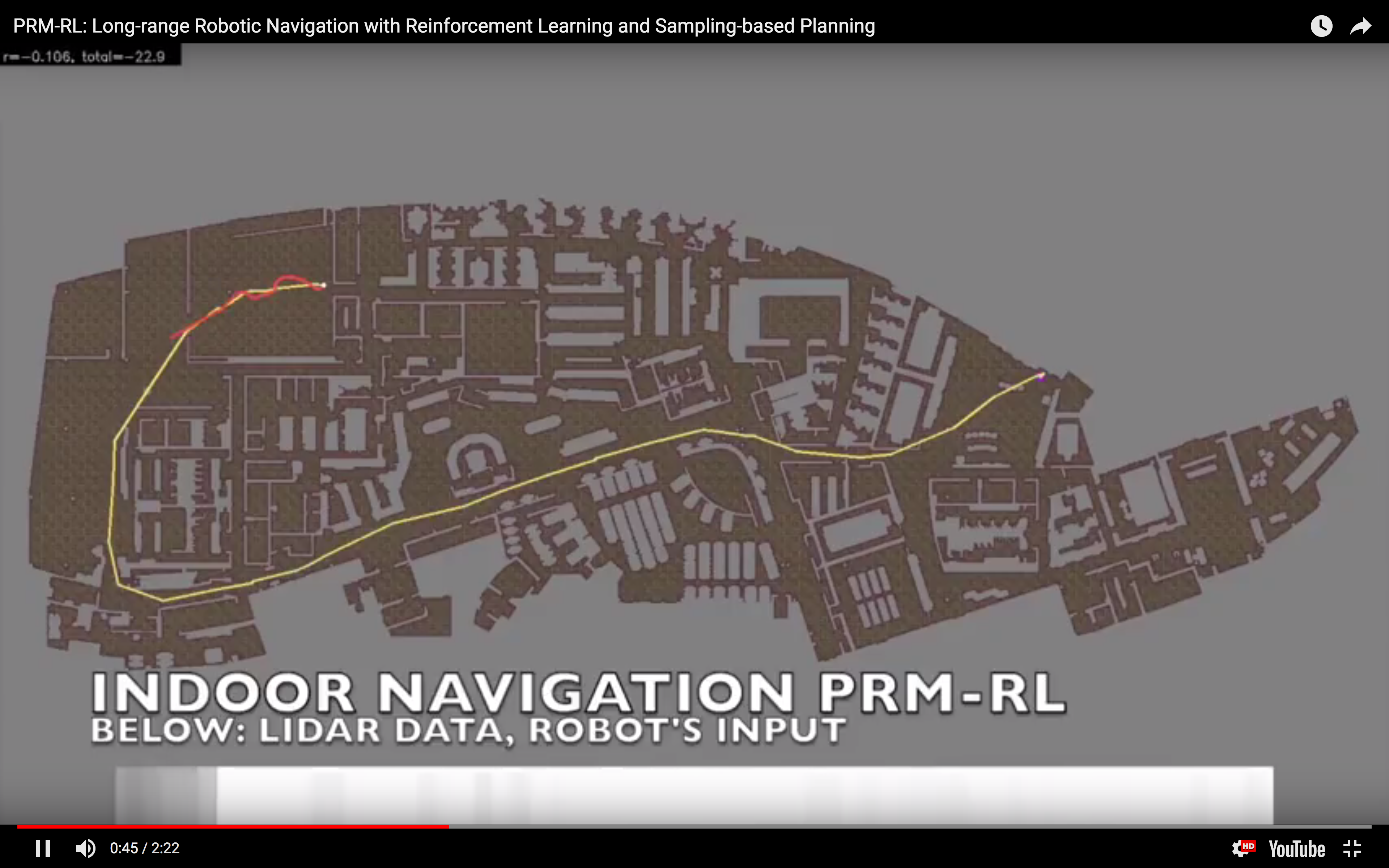 I often say "I teach robots to learn," but what does that mean, exactly? Well, now that one of the projects that I've worked on has been announced - and I mean, not just on
I often say "I teach robots to learn," but what does that mean, exactly? Well, now that one of the projects that I've worked on has been announced - and I mean, not just on 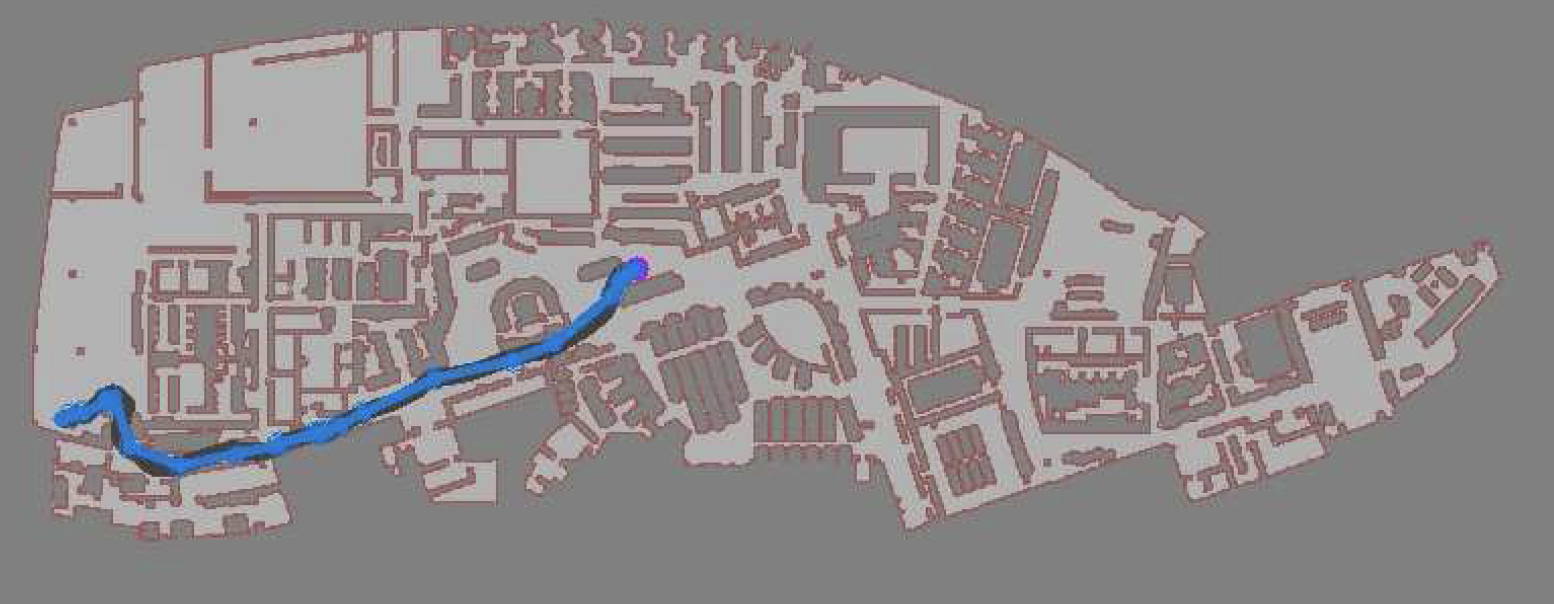 In simulation, our agent could traverse hundreds of meters using the PRM-RL approach, doing much better than a "straight-line" local planner which was our default alternative. While I didn't happen to have in my back pocket a hundred-meter-wide building instrumented with a mocap rig for our experiments, we were able to test a real robot on a smaller rig and showed that it worked well (no pictures, but you can see the map and the actual trajectories below; while the robot's behavior wasn't as good as we hoped, we debugged that to a networking issue that was adding a delay to commands sent to the robot, and not in our code itself; we'll fix this in a subsequent round).
In simulation, our agent could traverse hundreds of meters using the PRM-RL approach, doing much better than a "straight-line" local planner which was our default alternative. While I didn't happen to have in my back pocket a hundred-meter-wide building instrumented with a mocap rig for our experiments, we were able to test a real robot on a smaller rig and showed that it worked well (no pictures, but you can see the map and the actual trajectories below; while the robot's behavior wasn't as good as we hoped, we debugged that to a networking issue that was adding a delay to commands sent to the robot, and not in our code itself; we'll fix this in a subsequent round).
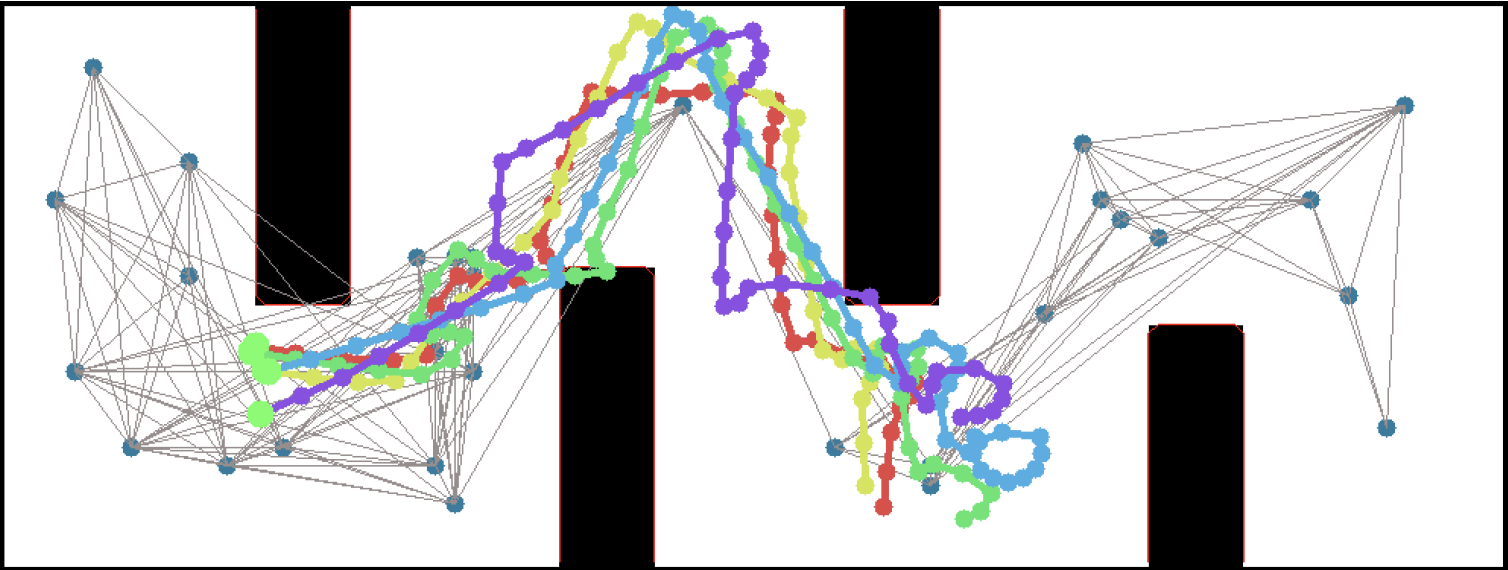 This work includes both our group working on office robot navigation - including Alexandra Faust, Oscar Ramirez, Marek Fiser, Kenneth Oslund, me, and James Davidson - and Alexandra's collaborator Lydia Tapia, with whom she worked on the aerial navigation also reported in the paper. Until the ICRA version comes out, you can find the preliminary version on arXiv:
This work includes both our group working on office robot navigation - including Alexandra Faust, Oscar Ramirez, Marek Fiser, Kenneth Oslund, me, and James Davidson - and Alexandra's collaborator Lydia Tapia, with whom she worked on the aerial navigation also reported in the paper. Until the ICRA version comes out, you can find the preliminary version on arXiv: