I operate with a long range planning horizon – I have lists of what I want to do in a day, a week, a month, a year, five years, and even my life. Not all my goals are fulfilled, of course, but I believe in the philosophy “People overestimate what they can do in a year, but underestimate what they can do in a decade.”
Recently, I’ve had that proven to me.
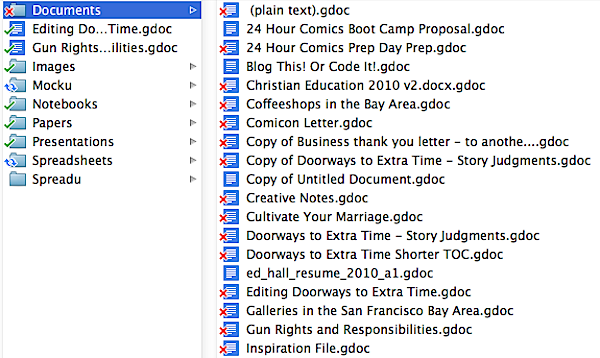
I’m an enormous packrat, and keep a huge variety of old papers and materials. Some people deal with clutter by adopting the philosophy “if you haven’t touched it in six months, throw it away.” Clearly, these people don’t write for a living.
So, in an old notebook, uncovered on one of my periodic archaeological expeditions in my library, I found an essay – a diary entry, really – written just before my 33rd birthday, entitled “Approaching 33” – and I find its perspective fascinating, especially when you compare what I was worried about then with where I am now.
“Approaching 33” was written on the fifth of November, 2011. That’s about five years after I split with my ex-fiancee, but a year before I met my future wife. It’s about a year after I finished my nearly decade-long slog to get my PhD, but ten years before when I got a job that truly used my degree. It’s about seven months after I reluctantly quit the dot-com I helped found to care for my dying father, but only about six months after my Dad actually died. And it’s about 2 months after 9/11, and about a month after disagreements over 9/11 caused huge rifts among my friends.
In that context, this is what I wrote on the fifth of November, 2011:
Approaching 33, your life seems seriously off-track. Your chances of following up on the PhD program are minimal – you will not get a good faculty job. And you are starting too late to tackle software development; you are behind the curve. Nor are you on track for being a writer.
The PhD program was a complete mistake. You wasted ten years of your life on a PhD and on your ex-fiancee. What a loser.
Now you approach middle fucking age – 38 – and are not on the career track, are not on the runway. You are stalled, lacking the crucial management, leadership and discipline skills you need to truly succeed.
Waste not time with useful affirmations – first understand the problem, set goals, fix things and move on. It is possible, only if you face clearly the challenges which are ahead of you.
You need to pick and embrace a career and a secondary vocation – your main path and your entertainment – in order to advance at either.
Without focus, you will not achieve. Or perhaps you are FULL OF SHIT.
Think Nixon. He had major successes before 33, but major defeats and did not run for office until your age. You can take the positive elements of his example – learn how to manage now, learn discipline now, learn leadership now, by whatever means are morally acceptable.
Then get a move on your career – it is possible. Do what you gotta do and move on with your life!
It appears I was bitter.
Apparently I couldn’t emotionally imagine I could succeed, but recognized, intellectually, that if I focused on what was wrong, and worked at it, then maybe, just maybe, I could fix it. And in the eleven years that have past … I mostly have.
Eleven years ago, I was enormously bitter, and regretted getting my PhD. It took five years, but that PhD and my work at my search-engine dot-com helped land me a great job, and after five more years of work I ended up at a job within that job that used every facet of my degree, from artificial intelligence to information retrieval to robotics to even computer graphics. My career took a serious left turn, but I never gave up trying, and eventually, I succeeded as a direct result of trying.
Eleven years ago, I felt enormously alone, having wasted a lot of time on a one-sided relationship that should have ended naturally after its first year, and having wasted many years after that either alone or hanging on to other relationships that were doomed not to work. But I never stopped looking, and hoping, and it took another couple of years before I found my best friend, and later married her.
Eleven years ago, I felt enormously unsure of my abilities as a software developer. At the dot-com I willingly stepped back from a software lead role when I was asked to deliver on an impossible schedule, a decision that was proved right almost immediately, and later took a quarter’s leave to finish my PhD, a decision that took ten years to prove itself. But even though both of those decisions were right, they started a downward spiral of self-confidence, as we sought out and brought in faster, more experienced developers to take over when I stepped back. While my predictions about the schedule were right, my colleagues nevertheless got more done, more quickly, ultimately culling out almost all of the code I wrote for the company. After a while, I felt I was contributing no more and, at the same time, needed to care for my dying father, so I left. But my father died shortly thereafter, six months before we expected. I found myself unable not to work, thinking it irresponsible even though I had savings, so I found a job at a software company whose technical lead was an old friend that who had been the fastest programmer I’d ever worked with in college, and now who had a decade of experience programming in industry – which is far more rigorous than programming in academia. On top of that, I was still recuperating from an RSI scare I’d had four years earlier, when I’d barely been able to write for six months, much less type. So I wrote those bitter words above when I was quite uncertain about whether I’d be able to cut it as a software developer.
Eleven years later — well, I still wish I could code faster. I’m surrounded by both younger and older programmers who are faster and snappier than I am, and I frequently feel like the dumbest person in the room. But I’ve worked hard to improve, and on top of that, slowly, I’ve come to recognize that I have indeed learned a few things – usually, the hard way, when I let someone talk me out of what I’m sure I know, and am later proved right – and have indeed picked up a few skills – synthetic and organizational skills, subtle and hard to measure, which aren’t needed for a small chunk of code but which are vital as projects grow larger in size and design docs and GANTT charts are needed to keep everything on track. I’d still love to code faster, to get up to speed faster, to be able to juggle more projects at once. But I’m learning, and I’ve launched things as a result of what I’ve learned.
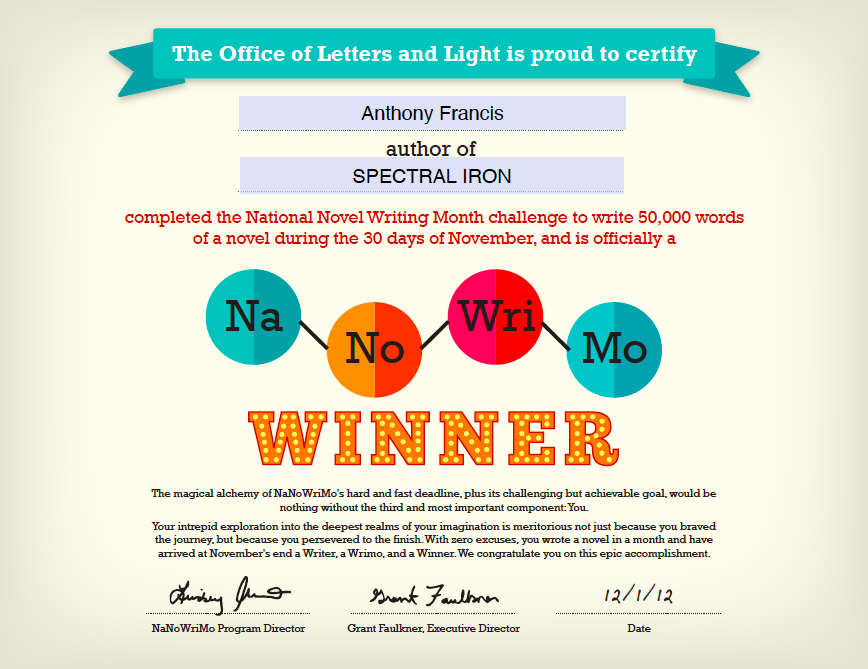
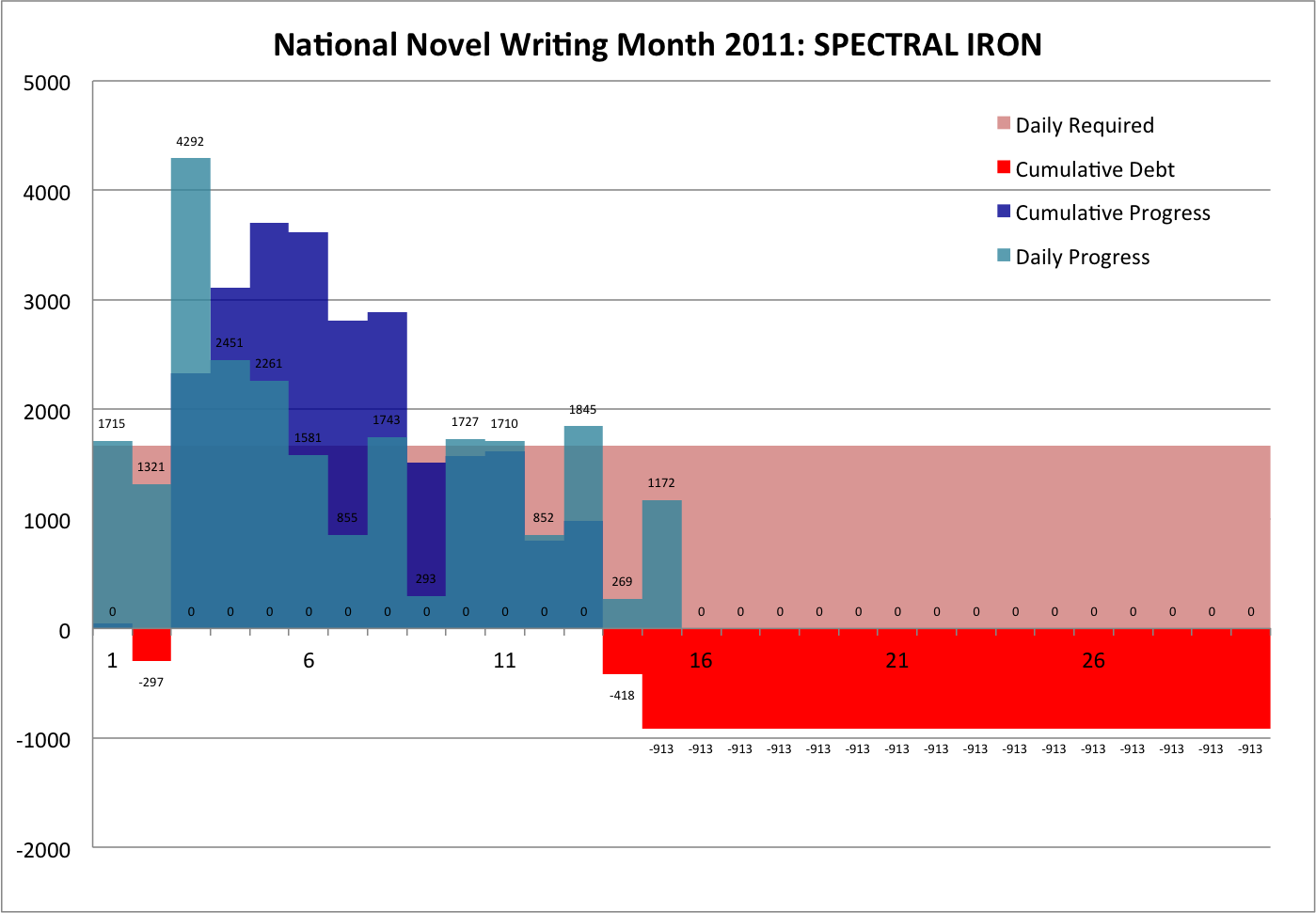
But the most important thing is that I’ve been writing. A year after I wrote that note, I gave National Novel Writing Month a try for the first time. I spent years trying to perfect my craft after that, ultimately finding a writing group focused just on writing and not on critique. Five years later, I gave National Novel Writing Month another try, and wrote FROST MOON, which went on to both win some minor awards and to peak high on a few minor bestseller lists. Five years after that, I’ve finished four novels, have starts to four more, and am still writing.
I have picked my vocation and avocation – I’m a computer programmer, and a writer. I actually think of it as having two jobs, a day job and a night job. At one point I thought I was going to transition to writing full time, and I still plan to, but then my job at work became tremendously exciting. Ten years from now, I hope to be a full time writer (and I already have my next “second job” picked out) but I’m in no rush to leave my current position; I’m going to see where it takes me. I learned that long ago when I had a chance to knuckle down and finish my PhD, or join an unrelated but exciting side project to build a robot pet. The choice to work on the emotion model for that pet indirectly landed me a job at two different search engines, even though it was the skills I learned in my PhD that I was ultimately hired for. The choice to keep working on that emotion model directly led to my current dream job, which is one of the few jobs in the world that required the combined skills of my PhD and side project. Now I’m going to do the same thing: follow the excitement.
Who knows where it will lead? Maybe it will help me develop the leadership skills that I complained about in “Approaching 33.” Maybe it will help me re-awaken my research interests and lead to that faculty job I wanted in “Approaching 33.” Maybe it will just help me build a nest egg so when I finally switch to writing full time, I can pursue it with gusto. Or maybe, just maybe, it’s helping me learn things I can’t even yet imagine how I’ll be using … when I turn 55.
After I sign off this blogpost, I’m going to write “Passing 44.” Most of that’s going to be private, but I can anticipate it. I’ll complain about problems I want to fix with my writing – I want it to be more clear, more compelling, more accessible. I’ll complain about problems I want to fix at work – I want to work faster, to ramp up more quickly, and to juggle more projects well while learning when to say no. And I’ll complain about martial arts and athletics – I want to ramp up working out, to return to running, and to resume my quest for a black belt. And there are more things I want to achieve – wanting to be a better husband, friend, pet owner, person – a lot of which I’m going to keep private until I write “Passing 44, seen from 55.”
I’m going to set bigger goals for the next ten years. Some of them might not come to pass, of course. I bet a year from now, I’ll have only seen the barest movement along some of those axes. But ten years from now … the sky’s the limit.
-the Centaur
Pictured: Me at 33 on the left, me at 44 on the right, over a backdrop shot at my home at 44, including a piece of art by my wife entitled "Petrified Coral".





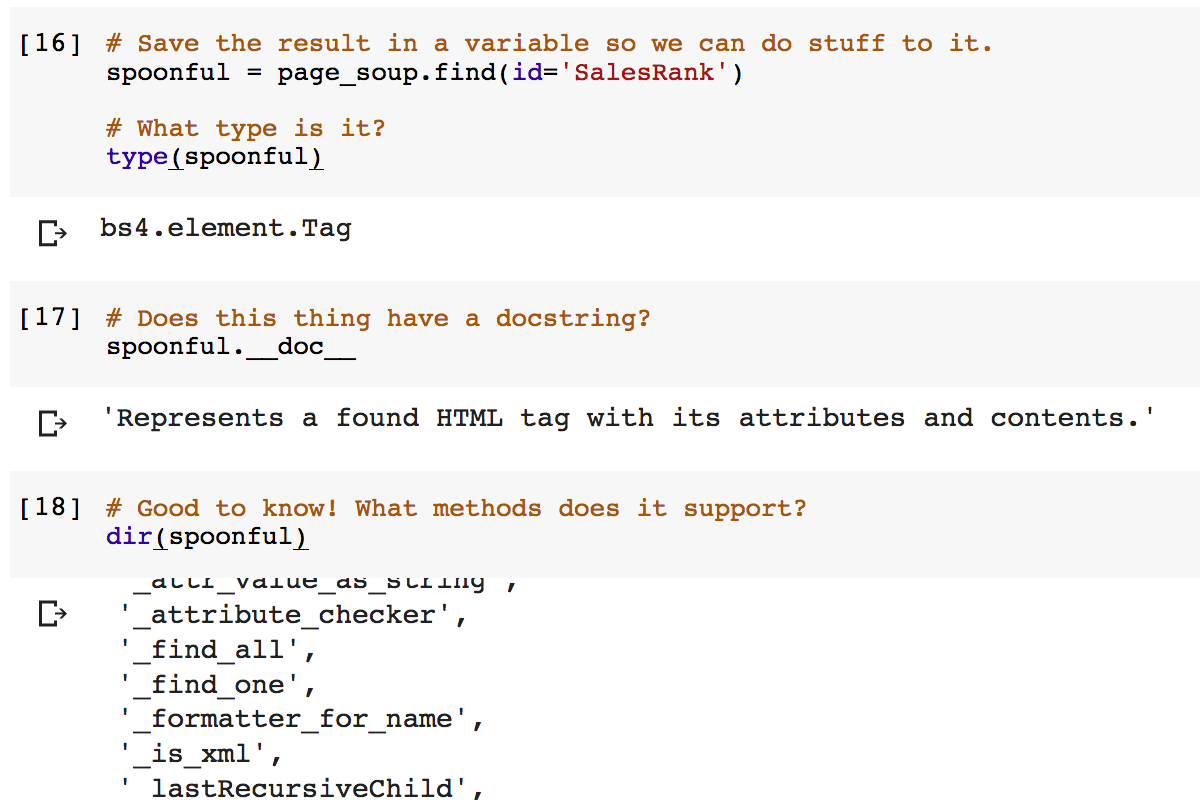 As an author, I'm interested in how well my books are doing: not only do I want people reading them, I also want to compare what my publisher and booksellers claim about my books with my actual sales. (Also, I want to know how close to retirement I am.)
In the past, I used to read a bunch of web pages on Amazon (and Barnes and Noble too, before they changed their format) and entered them into an Excel spreadsheet called "Writing Popularity" (but just as easily could have been called "Writing Obscurity", yuk yuk yuk). That was fine when I had one book, but now I have four novels and an anthology out. This could take out half an a hour or more, which I needed for valuable writing time. I needed a better system.
I knew about tools for parsing web pages, like the parsing library Beautiful Soup, but it had been half a decade since I touched that library and I just never had the time to sit down and do it. But, recently, I've realized the value of a great force multiplier for exploratory software development (and I don't mean Stack Exchange): interactive programming notebooks. Pioneered by Mathematica in 1988 and picked up by tools like iPython and its descendent Jupyter, an interactive programming notebook is like a mix of a command line - where you can dynamically enter commands and get answers - and literate programming, where code is written into the documents that document (and produce it). But Mathematica isn't the best tool for either web parsing or for producing code that will one day become a library - it's written in the Wolfram Language, which is optimized for mathematical computations - and Jupyter notebooks require setting up a Jupyter server or otherwise jumping through hoops.
Enter Google's Colaboratory.
Colab is a free service provided by Google that hosts Jupyter notebooks. It's got most of the standard libraries that you might need, it provides its own backends to run the code, and it saves copies of the notebooks to Google Drive, so you don't have to worry about acquiring software or running a server or even saving your data (but do please hit save). Because you can try code out and see the results right away, it's perfect on iterating ideas: no need to re-start a changed program, losing valuable seconds; if something doesn't work, you can tweak the code and try it right away. In this sense Colab has some of the force multiplier effects of a debugger, but it's far more powerful. Heck, in this version of the system you can ask a question on Stack Overflow right from the Help menu. How cool is that?
My prototyping session got a bit long, so rather than try to insert it inline here, I wrote this blog post in Colab! To read more, go take a look at the Colaboratory notebook itself, "A Sip of the Tracking Soup", available at:
As an author, I'm interested in how well my books are doing: not only do I want people reading them, I also want to compare what my publisher and booksellers claim about my books with my actual sales. (Also, I want to know how close to retirement I am.)
In the past, I used to read a bunch of web pages on Amazon (and Barnes and Noble too, before they changed their format) and entered them into an Excel spreadsheet called "Writing Popularity" (but just as easily could have been called "Writing Obscurity", yuk yuk yuk). That was fine when I had one book, but now I have four novels and an anthology out. This could take out half an a hour or more, which I needed for valuable writing time. I needed a better system.
I knew about tools for parsing web pages, like the parsing library Beautiful Soup, but it had been half a decade since I touched that library and I just never had the time to sit down and do it. But, recently, I've realized the value of a great force multiplier for exploratory software development (and I don't mean Stack Exchange): interactive programming notebooks. Pioneered by Mathematica in 1988 and picked up by tools like iPython and its descendent Jupyter, an interactive programming notebook is like a mix of a command line - where you can dynamically enter commands and get answers - and literate programming, where code is written into the documents that document (and produce it). But Mathematica isn't the best tool for either web parsing or for producing code that will one day become a library - it's written in the Wolfram Language, which is optimized for mathematical computations - and Jupyter notebooks require setting up a Jupyter server or otherwise jumping through hoops.
Enter Google's Colaboratory.
Colab is a free service provided by Google that hosts Jupyter notebooks. It's got most of the standard libraries that you might need, it provides its own backends to run the code, and it saves copies of the notebooks to Google Drive, so you don't have to worry about acquiring software or running a server or even saving your data (but do please hit save). Because you can try code out and see the results right away, it's perfect on iterating ideas: no need to re-start a changed program, losing valuable seconds; if something doesn't work, you can tweak the code and try it right away. In this sense Colab has some of the force multiplier effects of a debugger, but it's far more powerful. Heck, in this version of the system you can ask a question on Stack Overflow right from the Help menu. How cool is that?
My prototyping session got a bit long, so rather than try to insert it inline here, I wrote this blog post in Colab! To read more, go take a look at the Colaboratory notebook itself, "A Sip of the Tracking Soup", available at: 












 Let me completely up front about my motivation for writing this post: recently, I came across a paper which was similar to the work in my PhD thesis, but applied to a different area. The paper didn’t cite my work – in fact, its survey of related work in the area seemed to indicate that no prior work along the lines of mine existed – and when I alerted the authors to the omission, they informed me they’d cited all relevant work, and claimed “my obscure dissertation probably wasn’t relevant.” Clearly, I haven’t done a good enough job articulating or promoting my work, so I thought I should take a moment to explain what I did for my doctoral dissertation.
My research improved computer memory by modeling it after human memory. People remember different things in different contexts based on how different pieces of information are connected to one another. Even a word as simple as ‘ford’ can call different things to mind depending on whether you’ve bought a popular brand of car, watched the credits of an Indiana Jones movie, or tried to cross the shallow part of a river. Based on that human phenomenon, I built a memory retrieval engine that used context to remember relevant things more quickly.
My approach was based on a technique I called context directed spreading activation, which I argued was an advance over so-called “traditional” spreading activation. Spreading activation is a technique for finding information in a kind of computer memory called semantic networks, which model relationships in the human mind. A semantic network represents knowledge as a graph, with concepts as nodes and relationships between concepts as links, and traditional spreading activation finds information in that network by starting with a set of “query” nodes and propagating “activation” out on the links, like current in an electric circuit. The current that hits each node in the network determines how highly ranked the node is for a query. (If you understand circuits and spreading activation, and this description caused you to catch on fire, my apologies. I’ll be more precise in future blogposts. Roll with it).
The problem is, as semantic networks grow large, there’s a heck of a lot of activation to propagate. My approach, context directed spreading activation (CDSA), cuts this cost dramatically by making activation propagate over fewer types of links. In CDSA, each link has a type, each type has a node, and activation propagates only over links whose nodes are active (to a very rough first approximation, although in my evaluations I tested about every variant of this under the sun). Propagating over active links isn’t just cheaper than spreading activation over every link; it’s smarter: the same “query” nodes can activate different parts of the network, depending on which “context” nodes are active. So, if you design your network right, Harrison Ford is never going to occur to you if you’ve been thinking about cars.
I was a typical graduate student, and I thought my approach was so good, it was good for everything—so I built an entire cognitive architecture around the idea. (Cognitive architectures are general reasoning systems, normally built by teams of researchers, and building even a small one is part of the reason my PhD thesis took ten years, but I digress.) My cognitive architecture was called context sensitive asynchronous memory (CSAM), and it automatically collected context while the system was thinking, fed it into the context-directed spreading activation system, and incorporated dynamically remembered information into its ongoing thought processes using patch programs called integration mechanisms.
CSAM wasn’t just an idea: I built it out into a computer program called Nicole, and even published a workshop paper on it in 1997 called “
Let me completely up front about my motivation for writing this post: recently, I came across a paper which was similar to the work in my PhD thesis, but applied to a different area. The paper didn’t cite my work – in fact, its survey of related work in the area seemed to indicate that no prior work along the lines of mine existed – and when I alerted the authors to the omission, they informed me they’d cited all relevant work, and claimed “my obscure dissertation probably wasn’t relevant.” Clearly, I haven’t done a good enough job articulating or promoting my work, so I thought I should take a moment to explain what I did for my doctoral dissertation.
My research improved computer memory by modeling it after human memory. People remember different things in different contexts based on how different pieces of information are connected to one another. Even a word as simple as ‘ford’ can call different things to mind depending on whether you’ve bought a popular brand of car, watched the credits of an Indiana Jones movie, or tried to cross the shallow part of a river. Based on that human phenomenon, I built a memory retrieval engine that used context to remember relevant things more quickly.
My approach was based on a technique I called context directed spreading activation, which I argued was an advance over so-called “traditional” spreading activation. Spreading activation is a technique for finding information in a kind of computer memory called semantic networks, which model relationships in the human mind. A semantic network represents knowledge as a graph, with concepts as nodes and relationships between concepts as links, and traditional spreading activation finds information in that network by starting with a set of “query” nodes and propagating “activation” out on the links, like current in an electric circuit. The current that hits each node in the network determines how highly ranked the node is for a query. (If you understand circuits and spreading activation, and this description caused you to catch on fire, my apologies. I’ll be more precise in future blogposts. Roll with it).
The problem is, as semantic networks grow large, there’s a heck of a lot of activation to propagate. My approach, context directed spreading activation (CDSA), cuts this cost dramatically by making activation propagate over fewer types of links. In CDSA, each link has a type, each type has a node, and activation propagates only over links whose nodes are active (to a very rough first approximation, although in my evaluations I tested about every variant of this under the sun). Propagating over active links isn’t just cheaper than spreading activation over every link; it’s smarter: the same “query” nodes can activate different parts of the network, depending on which “context” nodes are active. So, if you design your network right, Harrison Ford is never going to occur to you if you’ve been thinking about cars.
I was a typical graduate student, and I thought my approach was so good, it was good for everything—so I built an entire cognitive architecture around the idea. (Cognitive architectures are general reasoning systems, normally built by teams of researchers, and building even a small one is part of the reason my PhD thesis took ten years, but I digress.) My cognitive architecture was called context sensitive asynchronous memory (CSAM), and it automatically collected context while the system was thinking, fed it into the context-directed spreading activation system, and incorporated dynamically remembered information into its ongoing thought processes using patch programs called integration mechanisms.
CSAM wasn’t just an idea: I built it out into a computer program called Nicole, and even published a workshop paper on it in 1997 called “